elasticsearch 7.4.2 进阶_elasticsearch 索引下面还能划分type-程序员宅基地
技术标签: elasticsearch 搜索
elasticsearch 7.4 进阶
SearchApi
ES支持两种基本方式检索
- 通过Rest request URI 发送搜索参数(uri + 检索参数)
- 通过Rest request body 发送 (uri + 请求体)
在kibana工具箱Dev Tools执行
GET /bank/_search?q=*&sort=account_number:asc
说明:
- /bank 查询bank索引下的数据
- _search 固定语法,查询
- q=* 查询所有
- sort=account_number:asc 排序规则,按照account_number字段升序排序
查询结果如下
{
"took" : 121,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "0",
"_score" : null,
"_source" : {
"account_number" : 0,
"balance" : 16623,
"firstname" : "Bradshaw",
"lastname" : "Mckenzie",
"age" : 29,
"gender" : "F",
"address" : "244 Columbus Place",
"employer" : "Euron",
"email" : "[email protected]",
"city" : "Hobucken",
"state" : "CO"
},
"sort" : [
0
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "1",
"_score" : null,
"_source" : {
"account_number" : 1,
"balance" : 39225,
"firstname" : "Amber",
"lastname" : "Duke",
"age" : 32,
"gender" : "M",
"address" : "880 Holmes Lane",
"employer" : "Pyrami",
"email" : "[email protected]",
"city" : "Brogan",
"state" : "IL"
},
"sort" : [
1
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "2",
"_score" : null,
"_source" : {
"account_number" : 2,
"balance" : 28838,
"firstname" : "Roberta",
"lastname" : "Bender",
"age" : 22,
"gender" : "F",
"address" : "560 Kingsway Place",
"employer" : "Chillium",
"email" : "[email protected]",
"city" : "Bennett",
"state" : "LA"
},
"sort" : [
2
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "3",
"_score" : null,
"_source" : {
"account_number" : 3,
"balance" : 44947,
"firstname" : "Levine",
"lastname" : "Burks",
"age" : 26,
"gender" : "F",
"address" : "328 Wilson Avenue",
"employer" : "Amtap",
"email" : "[email protected]",
"city" : "Cochranville",
"state" : "HI"
},
"sort" : [
3
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "4",
"_score" : null,
"_source" : {
"account_number" : 4,
"balance" : 27658,
"firstname" : "Rodriquez",
"lastname" : "Flores",
"age" : 31,
"gender" : "F",
"address" : "986 Wyckoff Avenue",
"employer" : "Tourmania",
"email" : "[email protected]",
"city" : "Eastvale",
"state" : "HI"
},
"sort" : [
4
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "5",
"_score" : null,
"_source" : {
"account_number" : 5,
"balance" : 29342,
"firstname" : "Leola",
"lastname" : "Stewart",
"age" : 30,
"gender" : "F",
"address" : "311 Elm Place",
"employer" : "Diginetic",
"email" : "[email protected]",
"city" : "Fairview",
"state" : "NJ"
},
"sort" : [
5
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "6",
"_score" : null,
"_source" : {
"account_number" : 6,
"balance" : 5686,
"firstname" : "Hattie",
"lastname" : "Bond",
"age" : 36,
"gender" : "M",
"address" : "671 Bristol Street",
"employer" : "Netagy",
"email" : "[email protected]",
"city" : "Dante",
"state" : "TN"
},
"sort" : [
6
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "7",
"_score" : null,
"_source" : {
"account_number" : 7,
"balance" : 39121,
"firstname" : "Levy",
"lastname" : "Richard",
"age" : 22,
"gender" : "M",
"address" : "820 Logan Street",
"employer" : "Teraprene",
"email" : "[email protected]",
"city" : "Shrewsbury",
"state" : "MO"
},
"sort" : [
7
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "8",
"_score" : null,
"_source" : {
"account_number" : 8,
"balance" : 48868,
"firstname" : "Jan",
"lastname" : "Burns",
"age" : 35,
"gender" : "M",
"address" : "699 Visitation Place",
"employer" : "Glasstep",
"email" : "[email protected]",
"city" : "Wakulla",
"state" : "AZ"
},
"sort" : [
8
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "9",
"_score" : null,
"_source" : {
"account_number" : 9,
"balance" : 24776,
"firstname" : "Opal",
"lastname" : "Meadows",
"age" : 39,
"gender" : "M",
"address" : "963 Neptune Avenue",
"employer" : "Cedward",
"email" : "[email protected]",
"city" : "Olney",
"state" : "OH"
},
"sort" : [
9
]
}
]
}
}
参数说明
-
took – Elasticsearch运行查询所需的时间(以毫秒为单位)
-
timed_out –搜索请求是否超时
-
_shards –搜索了多少个分片,以及成功,失败或跳过了多少个分片。
-
max_score –找到的最相关文件的分数
-
hits.total.value -找到了多少个匹配的文档
-
hits.sort -文档的排序位置(不按相关性得分排序时)
-
hits._score-文档的相关性得分(使用时不适用match_all)
在本示例 相应hits.total.value为1000,但发现记录里只有10条记录,这是因为
默认情况下,hits响应部分包括符合搜索条件的前10个文档,类似于Mysql数据库的分页。Mysql分页使用limt
select *from user limt 5; //返回结果集的前5行记录
select * from user limt 5,5 //从第6行开始,返回5行记录,也就是6, 7, 8, 9,10,这里的行索引是从0开始的
es也有类似的语法,可以使用 from 和 size 两个参数
GET /bank/_search?q=*&sort=account_number:asc&from=10&size=1
结果如下
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "10",
"_score" : null,
"_source" : {
"account_number" : 10,
"balance" : 46170,
"firstname" : "Dominique",
"lastname" : "Park",
"age" : 37,
"gender" : "F",
"address" : "100 Gatling Place",
"employer" : "Conjurica",
"email" : "[email protected]",
"city" : "Omar",
"state" : "NJ"
},
"sort" : [
10
]
}
]
}
}
Query DSL
语法格式
elasticsearch提供了一个可以执行查询的Json风格的DSL(domain-specific-language领域特定语言),这个称为 Query DSL。
Query DSL 基本使用
GET /bank/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"account_number": "asc"
},
{
"balance": {
"order": "desc"
}
}
],
"from": 10,
"size": 10,
"_source": ["account_number","balance"]
}
先按照 account_number 升序排序,再按照 balance 降序排序
- query —查询条件
- sort — 排序条件( “account_number”: "asc"为简写方式)
- match_all – 匹配所有
- _source —可以指定返回哪些字段,类似于Mysql中的 select name,age from user
match【匹配查询】
- 基本类型(非字符串),精确匹配
查询 1号用户的数据文档
GET /bank/_search
{
"query": {
"match": {
"account_number": 1
}
}
}
kibana查询结果如下
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"account_number" : 1,
"balance" : 39225,
"firstname" : "Amber",
"lastname" : "Duke",
"age" : 32,
"gender" : "M",
"address" : "880 Holmes Lane",
"employer" : "Pyrami",
"email" : "[email protected]",
"city" : "Brogan",
"state" : "IL"
}
}
]
}
}
使用match匹配查询,会有 max_score 以及 _score 得分情况,es会根据这个得分排序返回,得分越高越靠前
match也可以模糊匹配,匹配字段是字符串, es会将 字段匹配值进行分词,查询
GET /bank/_search
{
"query": {
"match": {
"address": "Kings"
}
}
}
结果如下
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 5.9908285,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "20",
"_score" : 5.9908285,
"_source" : {
"account_number" : 20,
"balance" : 16418,
"firstname" : "Elinor",
"lastname" : "Ratliff",
"age" : 36,
"gender" : "M",
"address" : "282 Kings Place",
"employer" : "Scentric",
"email" : "[email protected]",
"city" : "Ribera",
"state" : "WA"
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "722",
"_score" : 5.9908285,
"_source" : {
"account_number" : 722,
"balance" : 27256,
"firstname" : "Roberts",
"lastname" : "Beasley",
"age" : 34,
"gender" : "F",
"address" : "305 Kings Hwy",
"employer" : "Quintity",
"email" : "[email protected]",
"city" : "Hayden",
"state" : "PA"
}
}
]
}
}
match_phrase【短语匹配】
将需要匹配的值当成一个整体单词(不会被分词),进行检索
例如: “address”: “mill road”
如果使用match查询,es会将mill road分词成 mill 和road,只要address字段含有mill,road其一就会被检索出来,并给出相关性得分。
如果使用match_phrase,只有address含有 mill road这个短语的才会被检索出来,例如:
xxx mill road xxx会被检索出来, mill xxx road就不会被检索出来
GET /bank/_search
{
"query": {
"match_phrase": {
"address": "mill road"
}
}
}
multi_match【多字段匹配】
示例: 查询 addrss 或 status 包含 mill的文档数据
GET /bank/_search
{
"query": {
"multi_match": {
"query": "mill",
"fields": ["address","state"]
}
}
}
类似于Mysql中 address like ‘%mill%’ or status like '%mill%'
注意:
multi_match 也会进行分词查询
GET /bank/_search
{
"query": {
"multi_match": {
"query": "mill movico",
"fields": ["address","city"]
}
}
}
address字段包含 mill 或 movico
city字段包含 mill 或 movico
都会被检索出来
bool 【复合查询】
在复合查询中,会使用must,must_not以及should组合来查询
- must 必须满足
- must_not 必须不满足
- should 应该,可以满足,也可以不满足,满足最好(相关性得分会高)
GET /bank/_search
{
"query": {
"bool": {
"must": [
{ "match": { "gender": "F" } },
{"match":{"address":"mill"}}
]
}
}
}
- must 必须满足
含义: 查询 gender包含F的,同时,address包含mill的
除了有 must 还有一个 must_not(必须不是)
GET /bank/_search
{
"query": {
"bool": {
"must": [
{ "match": { "gender": "F" } },
{"match":{"address":"mill"}}
],
"must_not": [
{"match":{"age":"38"}}
]
}
}
}
说明:
查询 age 不是 38的数据
查看官方文档可知,must 和 should 会贡献相关性得分,换言之,must 和 should 匹配成功的话,相关性得分会高
filter【结果过滤】
filter会把不满足 fiter定义规则的给过滤掉,同时,filter不会贡献相关性得分
GET /bank/_search
{
"query": {
"bool": {
"filter": {
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}
}
}
}
}
}
term 查询
term级别查询将按照存储在倒排索引中的确切字词进行操作,这些查询通常用于数字,日期和枚举等结构化数据,而不是全文本字段。 或者,它们允许您制作低级查询,并在分析过程之前进行。
term是代表完全匹配,也就是精确查询,搜索前不会再对搜索词进行分词,所以我们的搜索词必须是文档分词集合中的一个。
所以: 查询数字,日期这种的可以使用term,查询文本类型的使用match
总结: 精确匹配的几种方式
方式一: match_phrase
GET /bank/_search
{
"query": {
"match_phrase": {
"address": "Madison Street"
}
}
}
方式二: match + 字段.keyword
GET /bank/_search
{
"query": {
"match": {
"address.keyword": "Madison Street"
}
}
}
那么二者的区别是什么?
“match_phrase”: {
“address”: “Madison Street”
}
类似于Mysql中的 address like ‘%Madison Street%’
“match”: {
“address.keyword”: “Madison Street”
}
类似于Mysql中的 address = ‘Madison Street’
aggregations【执行聚合】
聚合提供了从数据中分组和提取数据的能力,最简单的聚合类似于 SQL GROUP BY和聚合函数
聚合简单的结构如下:
"aggregations" : {
"<aggregation_name>" : {
"<aggregation_type>" : {
<aggregation_body>
}
[,"meta" : { [<meta_data_body>] } ]?
[,"aggregations" : { [<sub_aggregation>]+ } ]?
}
[,"<aggregation_name_2>" : { ... } ]*
}
-
需求: 搜索address中包含mill的所有人的年龄分布以及平均年龄
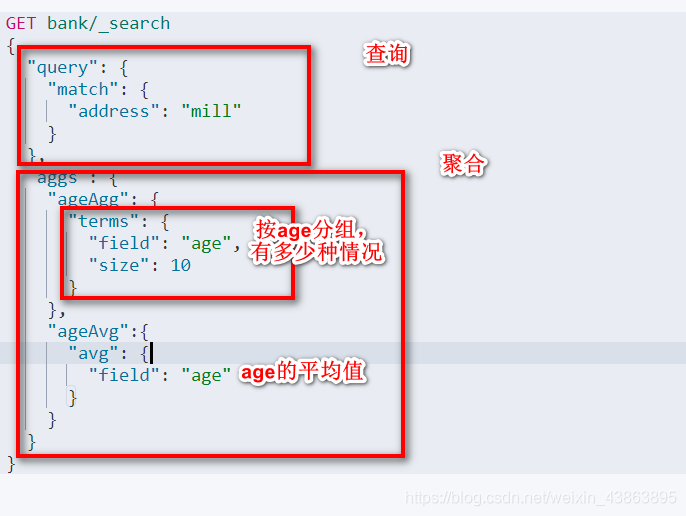

-
需求2 按照年龄聚合,并且求各个年龄段的平均工资
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"aggAvg": {
"avg": {
"field": "balance"
}
}
}
}
}
}

- 需求3 查出所有年龄分布,这些年龄段中性别为M的平均薪资和性别为F的平均薪资,以及这个年龄段的总体平均薪资
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"genderAgg": {
"terms": {
"field": "gender.keyword",
"size": 10
},
"aggs": {
"balanceAvg": {
"avg": {
"field": "balance"
}
}
}
},
"balanceAvg":{
"avg": {
"field": "balance"
}
}
}
}
}
}
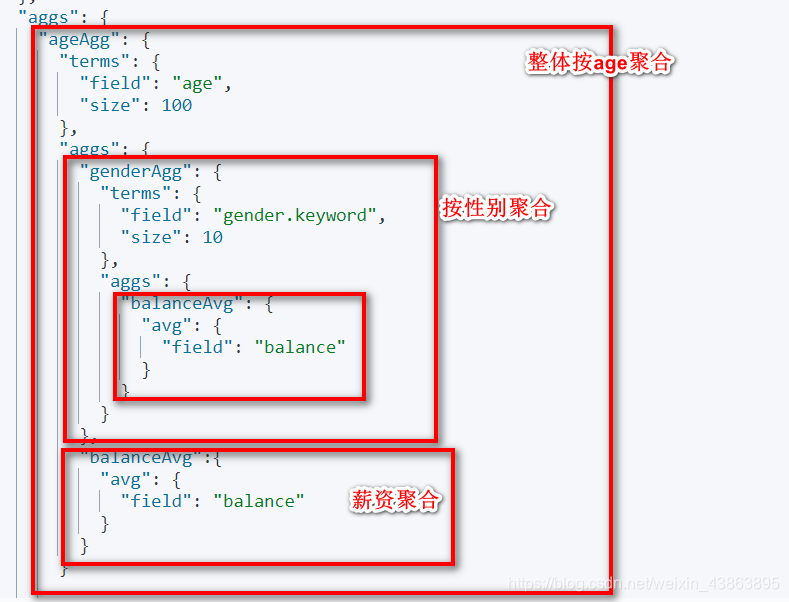
结果如下

mapping
mapping是类似于数据库中的表结构定义。
用来定义一个文档(document),以及它所包含的属性(field)是如何存储和索引的。
比如: 使用mapping用来定义
- 哪些字符串属性应该被看作全文本属性(full text field)
- 哪些属性包含数字、日期或地理位置
- 文档中的属性是否能被索引(_all 配置)
- 日期的格式
- 自定义映射规则来执行动态添加属性
注意

在es8版本将移除(type),所以以后可以将文档直接存储在某一个索引下面。
查询mapping 信息
GET bank/_mapping
结果如下:
{
"bank" : {
"mappings" : {
"properties" : {
"account_number" : {
"type" : "long"
},
"address" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"age" : {
"type" : "long"
},
"balance" : {
"type" : "long"
},
"city" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"email" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"employer" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"firstname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"gender" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"lastname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"state" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
创建索引并指定映射规则
PUT /my-index
{
"mappings": {
"properties": {
"age": { "type": "integer" },
"email": { "type": "keyword" },
"name": { "type": "text" }
}
}
}
注意: type 为 text 的会被分词检索,keyword不会被分词检索,当成关键字整体匹配。
添加新的字段映射
PUT /my-index/_mapping
{
"properties": {
"employee-id": {
"type": "keyword",
"index": false
}
}
}
index 为false,表示该字段不需要被索引,
index默认为true
更新映射
对于已经存在的字段映射,不能直接更新。可以创建新的索引,将数据迁移过去。
需求: 创建新的索引 new bank,修改之前字段的mapping映射,将bank数据迁移过去
PUT /newbank
{
"mappings": {
"properties": {
"account_number" : {
"type" : "long"
},
"address" : {
"type" : "text"
},
"age" : {
"type" : "integer"
},
"balance" : {
"type" : "long"
},
"city" : {
"type" : "keyword"
},
"email" : {
"type" : "keyword"
},
"employer" : {
"type" : "keyword"
},
"firstname" : {
"type" : "text"
},
"gender" : {
"type" : "keyword"
},
"lastname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"state" : {
"type" : "keyword"
}
}
}
}
数据迁移
POST _reindex
{
"source": {
"index": "bank",
"type": "account"
},
"dest": {
"index": "newbank"
}
}
注意:
将source下的数据迁移到dest下
如果旧索引下有 type,在source下写type,如果没有type就不用写
智能推荐
python入门指南txt-【杂谈】爬虫基础与快速入门指南-程序员宅基地
文章浏览阅读168次。今天给大家分享一下网络爬虫的基础知识,以及一些优秀的开源爬虫项目。网络爬虫主要是我们在面对新的任务,但自己又没有数据的时候,获取自己想要的数据的一种手段。因此我们有必要掌握一定的爬虫知识,从而更好的准备训练数据集。作者 | 言有三编辑 | 言有三1 前端网页基础在介绍爬虫之前我们先介绍一下网页基础,理解前端网页有利于我们对后面爬虫的学习,它是爬虫的基础之一。1.网页构成通常来说网页由三部分组成,分..._python入门指南 小说 txt
已解决java.lang.NullPointerException异常的正确解决方法,亲测有效!!!_tinyumbrella安装java.lang.nullpointerexception-程序员宅基地
文章浏览阅读5.3w次,点赞22次,收藏20次。在Java编程中NullPointerException是最常见的运行时异常之一,这种异常在我们访问一个空引用变量中的字段、方法或者对象时会触发。_tinyumbrella安装java.lang.nullpointerexception
如何为微信小程序添加微信支付和小程序支付功能-程序员宅基地
文章浏览阅读120次。获取微信支付相关信息 审核通过后,可以获取到一些重要的信息,包括商户号(mch_id)、密钥(key)、AppID(appid)、AppSecret(appsecret)等。处理支付回调 在用户支付成功后,微信会将支付结果通知到一个指定的URL中。我们需要在自己的服务器上处理这个支付结果,以便更新订单状态等。注册微信商户号 首先,需要在微信支付平台上注册一个微信商户号。生成签名 在发起支付请求之前,需要对请求参数进行签名。在实际的开发中,需要根据自己的业务需求进行参数的设置和处理。
LiteOS内核教程04 | 信号量(用于任务间同步)_信号量如何控制任务间的同步关系-程序员宅基地
文章浏览阅读1.5k次,点赞2次,收藏4次。本文首发于公众号『mculover666』,在学习本教程的过程中,可以登录华为云论坛小熊派板块进行发帖交流!1. LiteOS内核的信号量1.1.信号量在多任务操作系统中,不同的任务之间需要同步运行,信号量功能可以为用户提供这方面的支持。信号量(Semaphore)是一种实现任务间通信的机制,实现任务之间同步或临界资源的互斥访问。1.2. 信号量的使用方式信号量可以被任务获取或者申请..._信号量如何控制任务间的同步关系
Koa-MiniProgram:构建微信小程序的高效框架-程序员宅基地
文章浏览阅读282次,点赞3次,收藏7次。Koa-MiniProgram:构建微信小程序的高效框架项目地址:https://gitcode.com/ikcamp/koa-miniprogramKoa-MiniProgram 是一个基于 Koa 的微信小程序开发框架,它旨在提升小程序开发效率和代码可维护性。通过利用 Koa 的中间件机制,你可以更方便地组织业务逻辑,让代码结构更加清晰。技术分析中间件机制Koa 的核心在于它的中间件...
C语言-最小生成树(Kruskal算法)_6-1 最小生成树(克鲁斯卡尔算法) c语言-程序员宅基地
文章浏览阅读1.1w次,点赞45次,收藏340次。创建边集图(CreateEdgeGraph)打印图(print)排序函数(sort)顶点下标查找函数(LocateVex)查找双亲函数(FindRoot)克鲁斯卡尔算法(MiniSpanTree_Kruskal)克鲁斯卡尔算法简单的来说就是:每次选取最短边,但不能构成回路。克鲁斯卡尔算法的关键用那种方式存储图才合适?如果用邻接矩阵和邻接表,每次寻找最短边都要搜索所有边,故邻接矩阵和邻接表均不合适!改进图的存储:边集数组。EdgeGraph中包含了两个数组和顶点数、边._6-1 最小生成树(克鲁斯卡尔算法) c语言
随便推点
前端模拟列表的数组数据进行筛选_微信h5页面列表前端按列筛选-程序员宅基地
文章浏览阅读279次。前端模拟列表的数组数据进行筛选_微信h5页面列表前端按列筛选
重庆成人自考本科学校重要吗?-程序员宅基地
文章浏览阅读188次。自考选择主考院校一定要弄清楚报考院校毕业的规定,学士学位的规定。有些报考院校会有额外的规定,比如毕业论文优良,或者高于中等水平的平均成绩。
[FAQ21281]android P分区表中odmdtbo与dtbo分区的说明-程序员宅基地
文章浏览阅读552次。1. 对于需要OTA(O to P)升级到P版本的Project,分区layout必须与O版本完全一致,因此,请配置。虽然android P分区表中可以同时看到odmdtbo与dtbo分区,但实际上,ptgen在build生成的。Android O版本odmdtbo.img,在Android P版本改名成dtbo.img。此时build会生成odmdtbo.img,对应下载到odmdtbo分区。此时build会生成dtbo.img,对应下载到dtbo分区。_odmdtbo
vscode中配置.wxss和.wxml语法高亮和不全插件_vscode检查wxml语法-程序员宅基地
文章浏览阅读9.5k次。vscode默认无法识别wxml和wxss语法, 1、打开编辑器,选择微信文件,点击右下角的纯文本。然后选择相应匹配的识别格式,css和htmlimage.png但是强大的vscode自然有解决办法,我们点击纯文本会发现image.png所以我们只要将wxml关联成html就可以语法高亮了..._vscode检查wxml语法
大数据技术未来发展前景及趋势分析_大数据技术的发展方向-程序员宅基地
文章浏览阅读5.7k次。流大数据分析Storm: Apache Storm是一种开源的分布式实时计算系统。Storm加速了流数据处理的过程,为Hadoop批处理提供实时数据处理。Spark: Spark是一个兼容Hadoop数据源的内存数据处理平台,运行速度相比于HadoopMapReduce更快。Spark适合机器学习以及交互式数据查询工作,包含Scala、Python和Java API,这更有利于开发人员使用..._大数据技术的发展方向
Abaqus学习-初识Abaqus(悬臂梁)_abaqus悬臂梁-程序员宅基地
文章浏览阅读2k次,点赞2次,收藏8次。调整为HyperViewmo模式,使用Ctrl+鼠标键进行移动放大旋转PartpropertyAbaqus有自己的单位体系,在输入数值时不用带单位将材料赋给悬臂梁,为建立set,选中悬臂梁中键确认装配即使一个元件也要装配,此处只需点击创建和OK即可。Step创建step-1,此处默认即可;建立输出S/U接触-无Load-施加载荷和约束,载荷不可加到初始步,边界条件可以Mesh-网格的质量对计算结果十分钟重要布种赋予网格类型此处默认此处默认Mech._abaqus悬臂梁