大模型PEFT技术原理(一):BitFit、Prefix Tuning、Prompt Tuning_peft中的主流技术方案-程序员宅基地
随着预训练模型的参数越来越大,尤其是175B参数大小的GPT3发布以来,让很多中小公司和个人研究员对于大模型的全量微调望而却步,近年来研究者们提出了各种各样的参数高效迁移学习方法(Parameter-efficient Transfer Learning),即固定住Pretrain Language model(PLM)的大部分参数,仅调整模型的一小部分参数来达到与全部参数的微调接近的效果(调整的可以是模型自有的参数,也可以是额外加入的一些参数)。本文将介绍一些常见的参数高效微调技术,比如:BitFit、Prefix Tuning、Prompt Tuning、P-Tuning、P-Tuning v2、Adapter Tuning及其变体、LoRA、AdaLoRA、QLoRA、MAM Adapter、UniPELT等。
1、BitFit
论文地址:https://aclanthology.org/2022.acl-short.1.pdf
代码地址:https://github.com/benzakenelad/BitFit
BitFIt只对模型的bias进行微调。在小规模-中等规模的训练数据上,BitFit的性能与全量微调的性能相当,甚至有可能超过,在大规模训练数据上,与其他fine-tuning方法也差不多。在大模型中bias存在Q,K,V,MLP,LayerNorm中,具体公式如下:
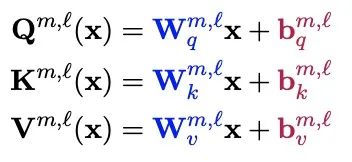
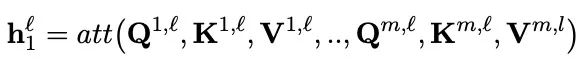
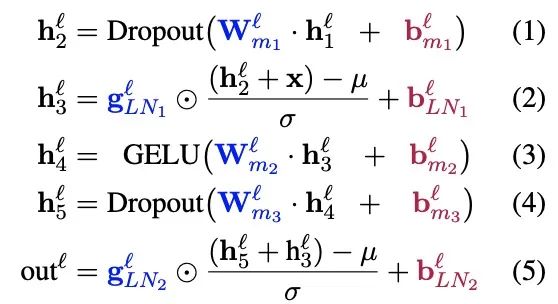
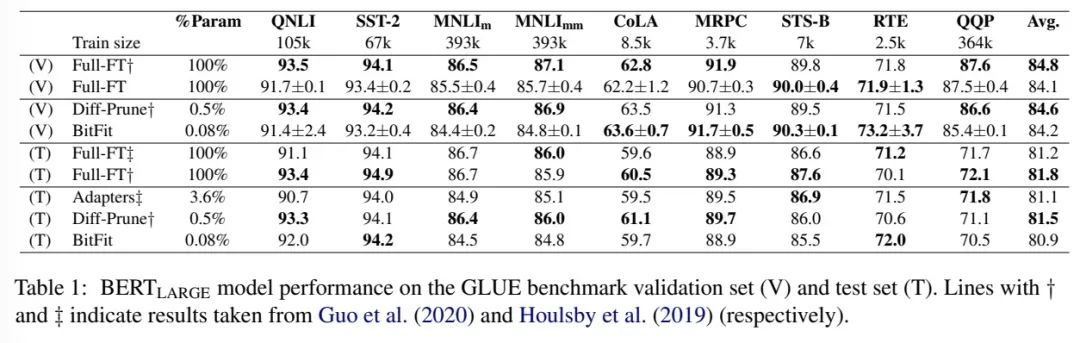
在Bert-Base/Bert-Large这种模型里,bias参数仅占模型全部参数量的0.08%~0.09%。但是通过在Bert-Large模型上基于GLUE数据集进行了 BitFit、Adapter和Diff-Pruning的效果对比发现,BitFit在参数量远小于Adapter、Diff-Pruning的情况下,效果与Adapter、Diff-Pruning想当,甚至在某些任务上略优于Adapter、Diff-Pruning。
通过Bitfit训练前后的参数对比,发现很多bias参数没有太多变化,例如跟计算key所涉及到的bias参数。发现其中计算query与中间MLP层的bias(将特征维度从N放大到4N的FFN层——将输入从768d转化为到3072d)变化最为明显,只更新这两类bias参数也能达到不错的效果,反之,固定其中任何一者,模型的效果都有较大损失。
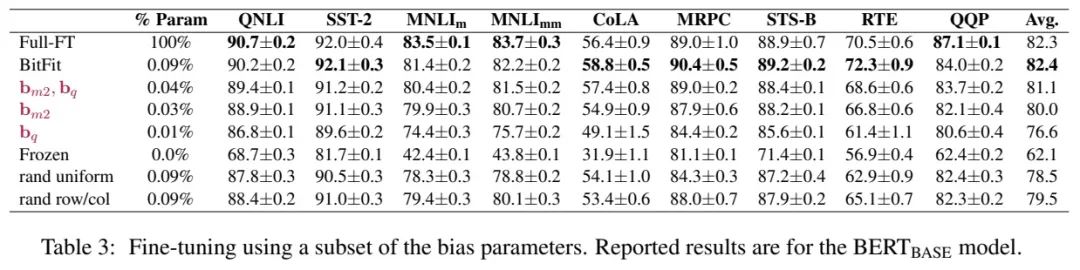
作者给出了Hugging Face与BitFit参数的映射关系表,如下所示:

2、Prefix Tuning
论文地址:https://arxiv.org/pdf/2101.00190.pdf
代码地址:https://github.com/XiangLi1999/PrefixTuning
prefix-tuning方法是一个轻量级的fine-tuning方法用于自然语言处理的生成任务。该方法可以保持预训练语言模型参数固定(frozen),而只需要在task-specific vector(称为prefix)上进行优化。即只需要少量(约0.1%)的优化参数,即可以在量和小量数据上达到不错的效果。
针对不同的模型结构,需要构造不同的Prefix。
-
针对自回归架构模型:在句子前面添加前缀,得到
z = [PREFIX; x; y],合适的上文能够在固定 LM 的情况下去引导生成下文(比如:GPT3的上下文学习)。 -
针对编码器-解码器架构模型:Encoder和Decoder都增加了前缀,得到
z = [PREFIX1; x; PREFIX2; y]。Encoder端增加前缀是为了引导输入部分的编码,Decoder 端增加前缀是为了引导后续token的生成。

如上图所示, 表示prefix indices序列,
表示prefix的长度。Prefix-tuning通过初始化可训练矩阵
(维度为
)来存储prefix参数:
training objective与Fine-tuning相同,但语言模型的参数 固定,仅仅prefix参数
是可训练参数。因此
是可训练的
的函数,当
时,
由
直接复制得到,对于
, 由于prefix activations始终在left context因此可以影响到
。
在实验上,直接更新 的参数会导致优化的不稳定以及表现上的极具下降。因此通过使用较小的矩阵
通过大型前馈神经网络(
)来reparametrize矩阵
:
其中, 和
在相同的行维度(也就是相同的prefix length), 但不同的列维度。当训练完成后,reparametrization参数被丢掉,仅仅
需要被保存下来。
实验中对比了Fine Tuning和Prefix Tuning在E2E、WebNLG和DART三个table-to-text任务上的效果:
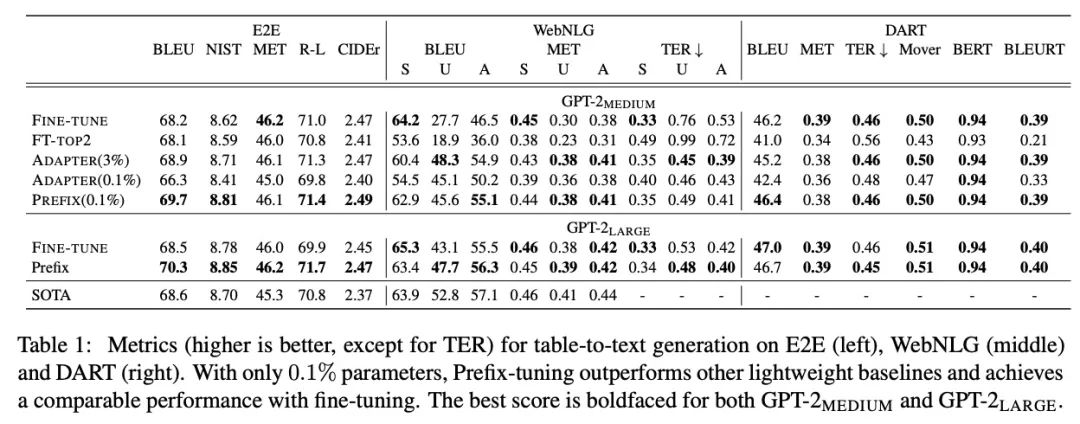
3、Prompt Tuning
论文地址:https://arxiv.org/pdf/2104.08691.pdf
代码地址:https://github.com/google-research/prompt-tuning
Prompt Tuning可以看作是Prefix Tuning的简化版本,面向NLU任务,进行了更全面的效果对比,并且在大模型上成功打平了LM微调的效果,它给每个任务定义了自己的Prompt,然后拼接到数据上作为输入,但只在输入层加入prompt tokens,并且不需要加入 MLP 进行调整来解决难训练的问题。通过反向传播更新参数来学习prompts,而不是人工设计prompts;同时冻结模型原始权重,只训练prompts参数,训练完以后,用同一个模型可以做多任务推理。
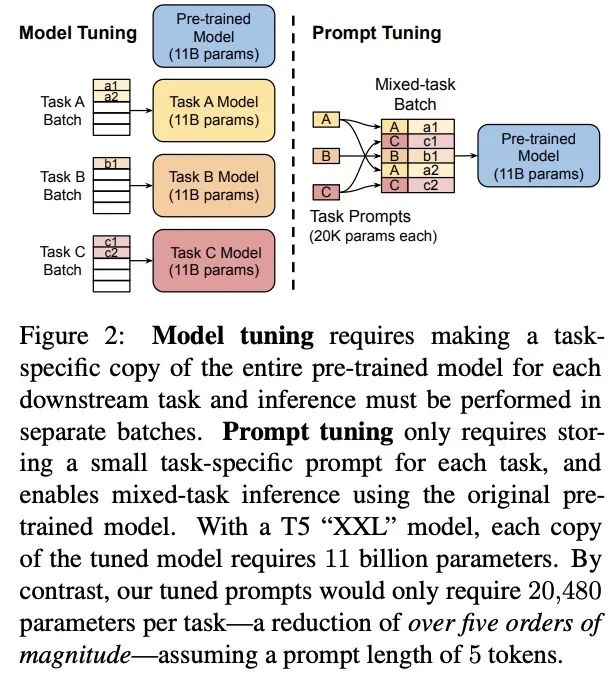
对比Prefix-Tunning,prompt-tuning的主要差异如下,
论文使用100个prefix token作为默认参数,大于以上prefix-tuning默认的10个token,不过差异在于prompt-Tunning只对输入层(Embedding)进行微调,而Prefix是对虚拟Token对应的上游layer全部进行微调。因此Prompt-Tunning的微调参数量级要更小,且不需要修改原始模型结构,这是“简化”的来源。相同的prefix长度,Prompt-Tunning(<0.01%)微调的参数量级要比Prefix-Tunning(0.1%~1%)小10倍以上,如下图所示
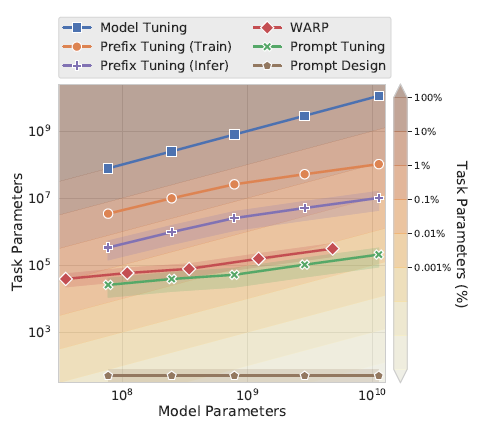
为什么上面prefix-tuning只微调embedding层效果就不好,放在prompt-tuning这里效果就好了呢?因为评估的任务不同无法直接对比,个人感觉有两个因素,一个是模型规模,另一个是继续预训练,前者的可能更大些,在下面的消融实验中会提到
效果&消融实验
在SuperGLUE任务上,随着模型参数的上升,PromptTunning快速拉近和模型微调的效果,110亿的T5模型(上面prefix-tuning使用的是15亿的GPT2),已经可以打平在下游多任务联合微调的LM模型,并且远远的甩开了Prompt Design(GPT3 few-shot)
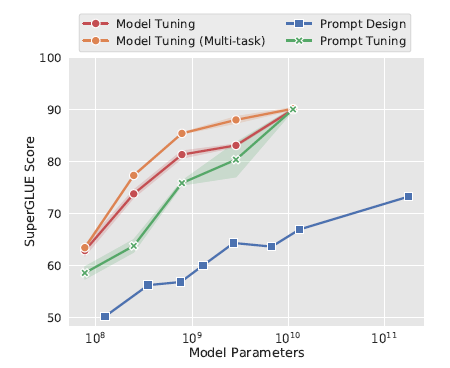
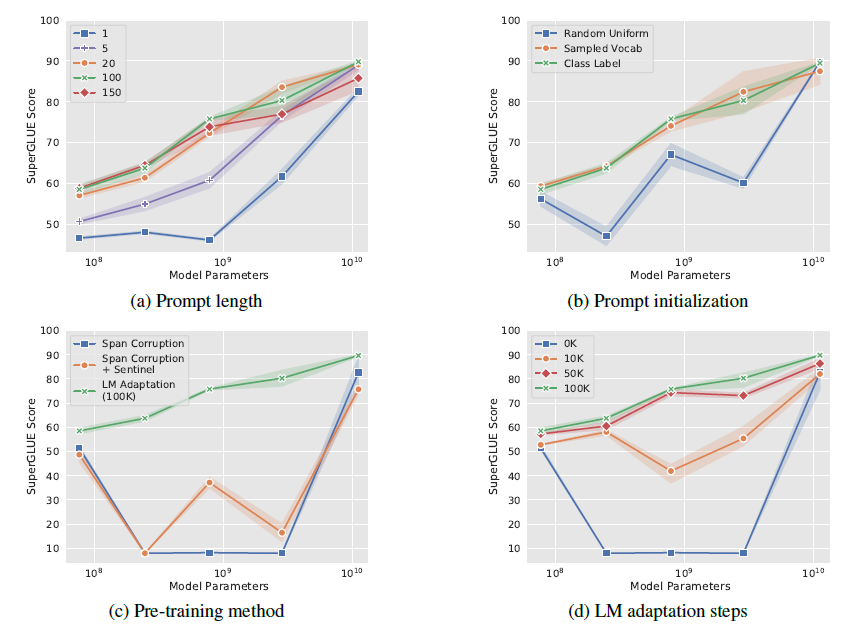
作者也做了全面的消融实验,包括以下4个方面,最核心的感受就是只要模型足够够大一切都好说
-
prompt长度(a):固定其他参数,作者尝试了{1,5,20,100,150}, Prompt token 的长度在20左右时的表现已经不错(超过20之后,提升Prompt token长度,对模型的性能提升不明显了),同样的,这个gap也会随着模型参数规模的提升而减小(即对于超大规模模型而言,即使 Prompt token 长度很短,对性能也不会有太大的影响);
-
Prompt初始化(b): 作者尝试了随机uniform初始化,用标签文本空间初始化,和用Top5K高频词采样初始化,在10^8规模,类标签词初始化效果最好。作者发现预测label也会在对应prompt空间内。不过到百亿规模后,初始化带来的影响就会消失;
-
T5继续预训练(c):作者认为T5本身的Span Corruption预训练目标和掩码词,并不适合冻结LM的场景,因为在微调中模型可以调整预训练目标和下游目标的差异,而只使用prompt可能无法弥合差异。其实这里已经能看出En-Dn框架在生成场景下没有GPT这样的Decoder来的自然。因此作者基于LM目标对T5进行继续预训练;
-
继续预训练step(d):以上的继续预训练steps,继续预训练步数越高,模型效果在不同模型规模上越单调;
可解释性
考虑Prompt-Tunning使用Embedding来表征指令,可解释性较差。作者使用cosine距离来搜索prompt embedding对应的Top5近邻。发现如下:
-
embedding的近邻出现语义相似的cluster,例如{ Technology / technology / Technologies/ technological / technologies }, 说明连续prompt实际可能是相关离散prompt词的聚合语义
-
当连续prompt较长(len=100), 存在多个prompt token的KNN相同:个人认为这和prefix-tuning使用MLP那里我的猜测相似,prompt应该是一个整体
-
使用标签词初始化,微调后标签词也大概率会出现在prompt的KNN中,说明初始化可以提供更好的prior信息加速收敛
智能推荐
Postgresql 数据库时区(timezone)设置,以及TIMESTAMPTZ和TIMESTAMP数据类型的选择-程序员宅基地
文章浏览阅读2.1w次,点赞12次,收藏18次。timestamp和timestamptz都占用8个字节,在存储时间时并没有本质的区别,都不携带时区信息。只是在insert保存数据和select给数据库客户端返回数据时处理方式不同。下边以具体示例解释这两种数据类型的差别,以及他们与数据库链接时区(session对应的时区)和postgresql数据库时区之间的关系。下边例子使用的数据库时区是Etc/UTC (GMT + 0),首先创建表,然后做相应操作:test_db=> CREATE TABLE test_table ( _timestamptz
模拟鼠标点击按钮的简单示例_bat脚本控制鼠标点击-程序员宅基地
文章浏览阅读7.2k次。原理 首先枚举到目标按钮所在程序的窗口,然后在该窗口内枚举控件获取控件的句柄,获取到按钮的句柄后可通过SendMessage或者PostMessage来发送消息模拟鼠标点击按钮等交互方式。但是因为枚举窗口和句柄都是使用WIN32 API,所以只能枚举到WIN32的控件,对于那些不是微软提供的控件则表示无能为力了。本示例简单地模拟一个往打字机里面写入数据,点击确认的方法。_bat脚本控制鼠标点击
筷云解读企业上云:为什么上云?选什么上云?_企业上云和用户上云啥意思-程序员宅基地
文章浏览阅读611次。近段时间,大家都在说企业上云,那么到底什么是企业上云?企业为什么要上云?应该怎么上呢?在新旧动能转换的关键时期,企业上云的确是可以驱动流程创新和业务创新,成为企业新的利润增长点。筷云作为国内知名的互联网生态体系构建者,以云服务为核心,赋能数字经济为使命,在助力企业上云方面有着丰富的经验。企业上云是什么?企业上云是指企业通过网络,将企业的基础设施、管理及业务部署到云端,利用网络便捷..._企业上云和用户上云啥意思
node、 node-sass 和sass-loader的版本对应问题_node-sass 版本-程序员宅基地
文章浏览阅读2.1k次。错误产生原因:node、 node-sass 和sass-loader的版本对应问题。_node-sass 版本
Java中的静态和非静态(有代码实例,超详细!)_java 静态-程序员宅基地
文章浏览阅读1.8k次,点赞10次,收藏39次。静态变量和方法是属于类的,而不属于类的实例或对象。它们可以通过类名直接访问,不需要创建对象。因此,静态成员常常用于描述与类本身有关的信息,比如常量、工具方法等。例如,Math类中的PI常量和abs()方法都是静态的。非静态变量和方法则是属于类的实例或对象的。它们必须依赖于对象的状态,才能进行相应的操作。因此,非静态成员常常用于描述类的实例状态,比如具有不同属性的学生或员工对象。例如,一个Person类中的name和age变量就是非静态的。_java 静态
关于tecplot动画的制作_tecplot动图-程序员宅基地
文章浏览阅读1.2w次。原文地址:关于tecplot动画的制作作者:Cherry参考文献一:http://hi.baidu.com/zhaoyj_111/blog/item/7939c318bb71e37cdab4bdbe.htmltecplot——画等高线和做动画的流程2008-10-10 11:22 Tecplot构筑结构网格有两种方式:point format和blockformat。_tecplot动图
随便推点
在preferenceScreen中加入自己设计的layout布局_能否在perferencescreen中加入linearlayout-程序员宅基地
文章浏览阅读4.9k次。本文来自:点击打开链接图1中上面的listtitle是一个listPreference,当你点击后会出现图2的效果,然后在图2中选择ABC其中一个,这个dialog会消失,并将选择的文本显示在图1中而下面的部分是在PreferenceScreen中嵌套一个PreferenceScreen,在内部的PreferenceScreen中使用android:@layout/your_layou_能否在perferencescreen中加入linearlayout
项目研发管理经验交流_研发经验分享-程序员宅基地
文章浏览阅读10w+次,点赞6次,收藏26次。最近,大BOSS要求我给集团内部的各项目研发组长进行一次培训,让我准备下,我当时一听有点懵,为什么是我? 内心挣扎了200ms后,我爽快的答应了! 回来后,我就在想,我要怎么做这个PPT呢?我当时想的不是我能不能完成,而是我要怎么结合自己这近一年的研发管理经验,来把这个PPT完成的很有料! 既然让我做,就有让我做的理由,我很忙,也没时间去想,咱也不敢说,咱也不敢问..._研发经验分享
spring-security入门4---自定义登录成功和登录失败的行为_spring sso 自定义登录错误-程序员宅基地
文章浏览阅读1.6k次。项目源码地址https://github.com/nieandsun/security_spring sso 自定义登录错误
TypeError: an integer is required (got type is tuple)-程序员宅基地
文章浏览阅读7.6k次。TypeError: an integer is required (got type is tuple ),这个错误。从字面意思理解,需要获取一个整型数据,而原代码是元组。需要做的就是,定位到错误的具体那行,将元组改为整型就行。我这边的是img_tr = [transforms.RandomResizedCrop((int(args.image_size), int(args.image_size)), (args.min_scale, args.max_scale))]将 (int(args.i_an integer is required
100%的BAT招聘岗位都考的知识,你精通了吗?-程序员宅基地
文章浏览阅读176次。程序 = 数据结构 + 算法 ——图灵奖得主,计算机科学家N.Wirth(沃斯)作为程序员,我们做机器学习也好,做Python开发也好,Java开..._bat春招主要考什么
沁恒蓝牙芯片CH58x系列学习与应用_ch58x_bleinit-程序员宅基地
文章浏览阅读1.9k次,点赞6次,收藏30次。在前人的基础上补充一个沁恒CH85x系列蓝牙central例程的记录_ch58x_bleinit