LightGBM win10下亲测可用,0.1版本,附最新版本的LightGBM python版安装方法
”LightGBM“ 的搜索结果
数据通要安装的软件包pip install kagglepip install pandaspip install matplotlibpip install lightgbm数据集下载kaggle competitions download -c interbank-internacional-2019RCC解释西班牙购物车购物指南。...
解压后需要cd到LightGBM/python-package目录下再次执行: pip install lightgbm --install-option=--gpu
一只小狐狸带你解锁NLP/ML/DL秘籍正文来源:Microstrong1 LightGBM简介GBDT (Gradient Boosting Decision Tree) 是机器学习中...

文章目录1 lightgbm的基本使用1.原生形式使用lightgbm2.sklearn接口形式的Lightgbm2.Lightgbm调参3.例子:下面就以一个乳腺癌数据的例子,看看我们应该怎么具体去调参:1. **第一步:学习率和迭代次数**2.**第二步:...
机器学习之lightGBM模型
标签: 机器学习

回归预测 | MATLAB实现基于LightGBM算法的数据回归预测(多指标,多图)
点击 机器学习算法与Python学习 ,选择加星标精彩内容不迷路来源:Microstrong,编辑:AI有道1. LightGBM简介GBDT (Gradient Boosting De...


1.Python实现LightGBM时间序列预测(完整源码和数据) anaconda + pycharm + python +Tensorflow 注意事项:保姆级注释,几乎一行一注释,方便小白入门学习! 2.代码特点:参数化编程、参数可方便更改、代码编程思路...
报错提示: ERROR: Command errored out with exit status 1: ... sys.argv[0] = '"'"'/tmp/pip-install-B6tTOW/lightgbm/setup.py'"'"'; __file__='"'"'/tmp/pip-install-B6tTOW/lightgbm/setup.py'"'"';f=get...

问题遇到的现象和发生背景 R语言使用lightgbm进行多标签分类,训练模型时出现以下错误: 问题相关代码,请勿粘贴截图 # 转换为lightgbm数据格式 dtrain (train[,4:77], label = train[,78:138]) dtest (test[,4:77],...
本文适合有集成学习与XGBoost基础的读者了解LightGBM算法。 序 LightGBM是基于XGBoost的改进版,在处理样本量大、特征纬度高的数据时,XGBoost效率和可扩展性也不够理想,因为其在对树节点分裂时,需要扫描每一个...
1. LightGBM简介 GBDT (Gradient Boosting Decision Tree) 是机器学习中一个长盛不衰的模型,其主要思想是利用弱分类器(决策树)迭代训练以得到最优模型,该模型具有训练效果好、不易过拟合等优点。...
从网上找到的方法都是说可以通过使用homebrew库安装libomp来解决上述问题,但在我的环境中并不管用。我的解决方法是,不使用pip命令安装lightgbm。首先卸载pip命令安装的lightgbm。之后利用conda命令安装lightgbm。
lightGBM跨时间交叉验证.选择比较重要的特征,这些特征是禁得起跨时间交叉验证 逻辑回归/xgboost/lightgbm,线上跑lr模型,线下xgboost/lightgbm,上线之后需要监控不同信用分段的人群分布情况
个人学习LightGBM算法的笔记和实践
GDBT 1)对所有特征都按照特征的数值进行预排序。 2)在遍历分割点的时候用O(#data)的...LightGBM 重点:对模型训练时样本点的采样优化和特征维度的优化 原理 1.单边梯度采样算法(Grandient-based One-Side S...
之前的文章(pyspark lightGBM1和pyspark lightGBM2)介绍了pyspark下lightGBM算法的实现,本文将重点介绍下如何保存训练好的模型,直接上代码: from pyspark.sql import SparkSession from pyspark.ml.feature ...
使用集成模型LightGBM解决简单的回归预测任务
importmatplotlib.pylab as pltimportseaborn as snsimportlightgbm as lgbimportpandas as pdimportnumpy as npdata_df= pd.read_csv('train.csv')label= data_df['TARGET']feature= data_df.drop(['TARGET','ID'],...
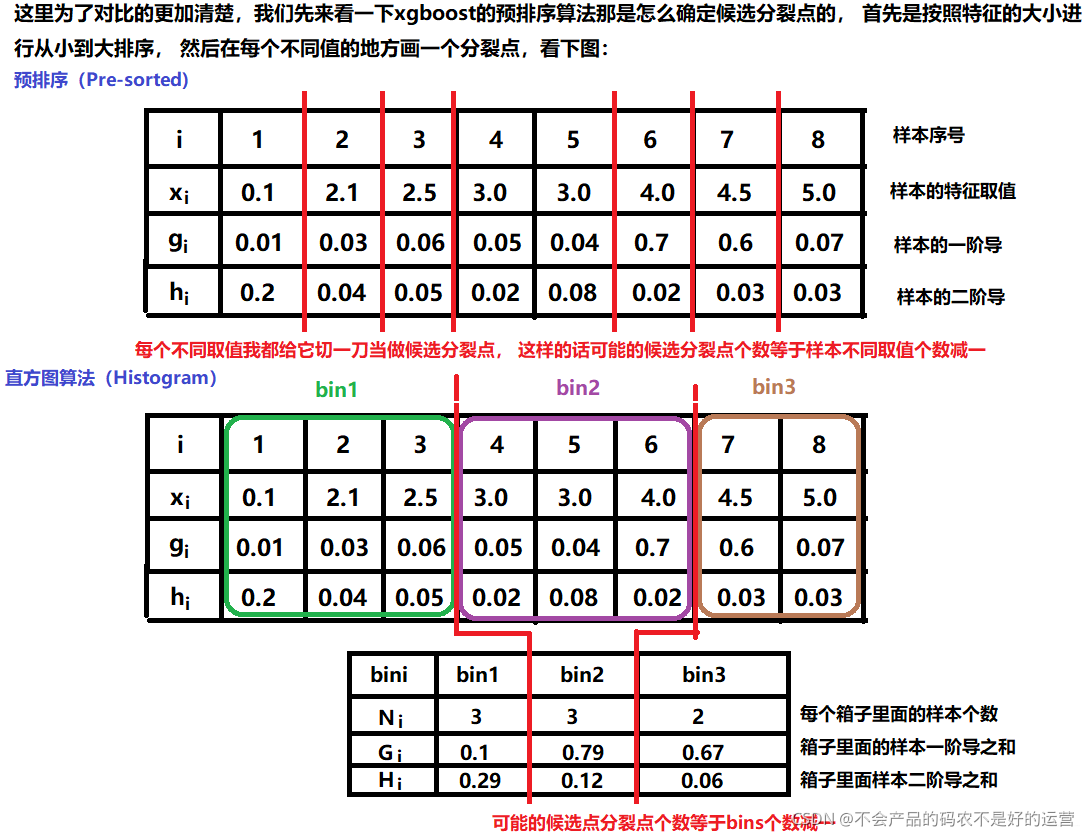


法工程师`常见面试问题总结之`LightGBM常见面试题总结

LightGBM算法引言1、LightGBM原理 引言 \quad \quadGBDT (Gradient Boosting Decision Tree) 是机器学习中一个长盛不衰的模型,其主要思想是利用弱分类器(决策树)迭代训练以得到最优模型,该模型具有训练效果好、...
推荐文章
- withRouter,非根组件获取路由参数_withrouter 只能取到路由中的一个参数-程序员宅基地
- ubuntu环境下QT5操作摄像头报错,cannot find -lpulse-mainloop-glib cannot find -lpulse cannot find -lglib-2.0_cannot find–lpulse-程序员宅基地
- 用jbpm_bpel学jwsdp的ant方式使用-程序员宅基地
- 输入数字判断星期几_html获取当前星期几-程序员宅基地
- SpringBoot整合Activiti7——实战之放假流程(会签)_activit7中会签-程序员宅基地
- 阿里云服务器收到挖矿病毒的攻击,导致基础的文件被病毒污染的问题和对应的处理解决方法-程序员宅基地
- 北京东城区空调维修办法,格力变频空调出现ph,到底是怎么回事?_格力变频空调ph代码-程序员宅基地
- vscode编辑器使用拓展插件background添加背景图片改变外观_background vscode-程序员宅基地
- android 简单打电话程序_android拨打电话的程序-程序员宅基地
- 第二届中国(泰州)国际装备高层次人才创新创业大赛_泰州市双创人才计划2022-程序员宅基地