
”MapReduce执行流程“ 的搜索结果
MapReduce的大体流程是这样的,如图所示:由图片可以看到mapreduce执行下来主要包含这样几个步骤1.首先对输入数据源进行切片2.master调度worker执行map任务3.worker读取输入源片段4.worker执行map任务,将任务输出...
Read:读取阶段MapTask会调用InputFormat中的getSplits方法来对文件进行切片切片之后,针对每一个Split,产生一个流用于读取数据数据是以Key-Value形式来产生,交给map方法来处理。每一个键值对触发调用一次map方法...
mapreduce
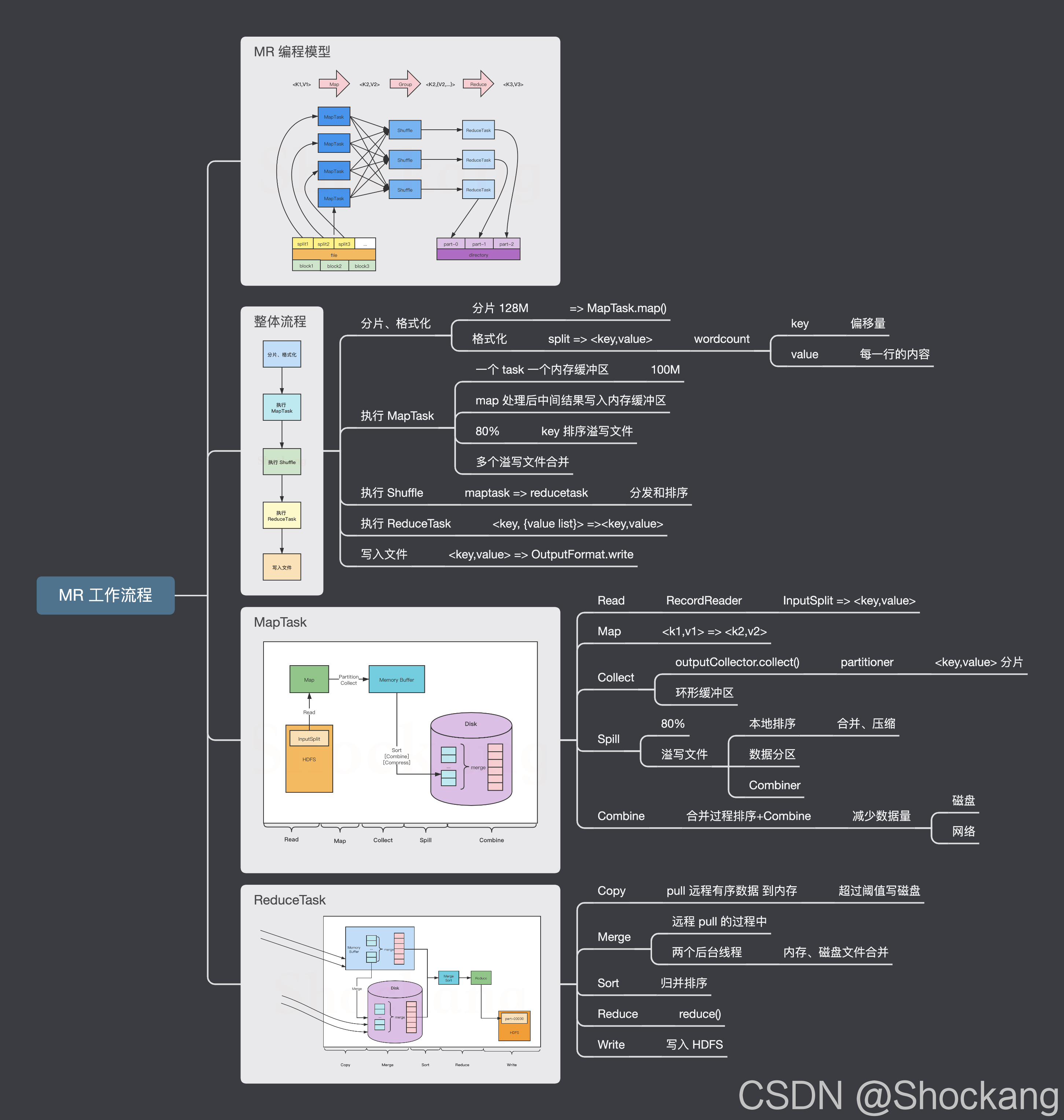
MapReduce的执行流程 MapReduce一共可以分为两个阶段 Map阶段和Reduce阶段、但是有一部分也可以划分为三个阶段(Map、Shuffle、Reduce) Map和Reduce阶段分属两台不同的主机,两者之间通过网络通信。 整个的...


mapreduce原理和介绍

MapReduce整体分为Map阶段,shuffle阶段和reduce阶段 map阶段 对输入的文件进行分片InpuSplit,每个分片由一个Mapper进程进行处理 对输入的分片内容按照一定的规则解析成键值对。默认是每行偏移量为...
本节将对 Hadoop MapReduce 的工作机制进行介绍,主要从 MapReduce 的作业执行流程和 Shuffle 过程方面进行阐述。通过加深对 MapReduce 工作机制的了解,可以使程序开发者更合理地使用 MapReduce 解决实际问题。 ...
1.hadoop 平台进程管理者文件系统的Namespace。它维护着文件系统树(filesystem tree)以及文件树中所有的文件和文件夹的元数据(metadata)。管理这些信息的文件有两个,分别是Namespace 镜像文件(Namespace image)和...
MapReduce流程
读完谷歌的MapReduce的论文,基本上就会对这个分布式模型设计有了初步的认识,这里就不过多...worker通过RPC与coordinator通信,每一个woker都会询问一个任务,从文件中读取输入,执行任务,并且将输出写入到files中。
(1)切片对输入文件进行切片,切片大小为最小切片(>=1)、最大...(3)执行每一个切片对应一个MapTask,将切片中的每行数据封装为k-v键值对,并执行一次map()方法,经过一系列逻辑运算,输出k-v键值对形式的结果。
MapReduce执行流程 输入和拆分: 不属于map和reduce的主要过程,但属于整个计算框架消耗时间的一部分,该部分会为正式的map准备数据。 分片(split)操作: split只是将源文件的内容分片形成一系列的...
在将Buffer中的键值对数据写入磁盘之前,先进行一次内存排序,排序的规则是:MapOutputBuffer内部有3个Buffer,排序是对键值对偏移位置的Buffer kvoffsets进行排序,保证每一个键值对所属的分区(Partition)按照...
org.apache.hadoop.mapreduce.server.jobtracker.TaskTracker对象(该TaskTracker对象是在JobTracker的视角看到的结构),加入到队列HashMap taskTrackers中,同时还要计算该TaskTracker所在的host节点上TaskTracker...
Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上; 2 为什么要用mapreduce 海量数据在单机上处理因为硬件资源限制,无法胜任 ...
MapReduce执行流程以及shuffle是什么Map执行流程Reduce执行流程shuffle是什么 Map执行流程 就拿Wordcount来举例吧,明白了Wordcount就明白了流程 1.当一个大的文件要执行MapReduce任务时会根据HDFS的文件块大小进行...
MapReduce执行流程输入和拆分:不属于map和reduce的主要过程,但属于整个计算框架消耗时间的一部分,该部分会为正式的map准备数据。分片(split)操作:split只是将源文件的内容分片形成一系列的 InputSplit,每个 ...
以下是MapReduce执行流程图:  MapReduce执行流程包括以下步骤: 1. Map阶段:将输入数据按照一定规则分割...
MapReduce执行流程详解(Yarn模式)一.Reduce工作流程图二.MR整体执行流程(Yarn模式) 一.Reduce工作流程图 二.MR整体执行流程(Yarn模式) 1.在MapReduce程序读取文件的输入目录上存放相应的文件。 2.客户端程序...
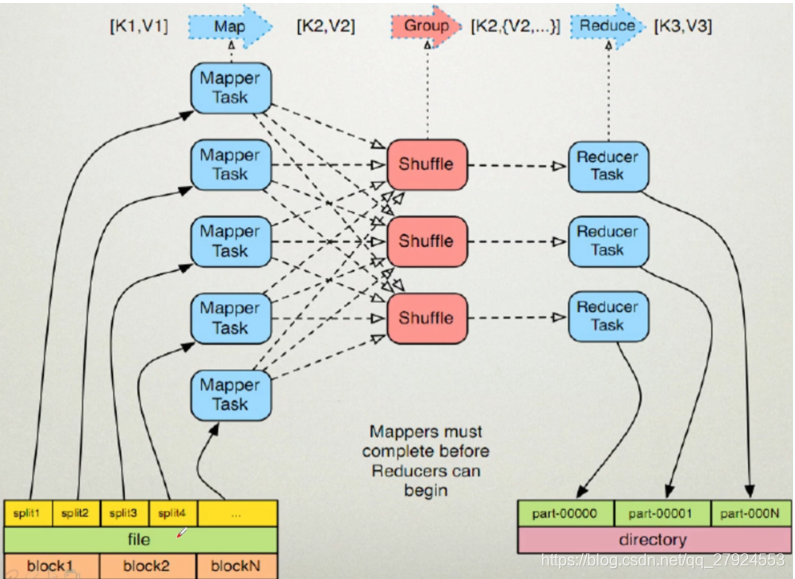
一、MapReduce执行过程 MapReduce运行时,首先通过Map读取HDFS中的数据,然后经过拆分,将每个文件中的每行数据分拆成键值对,最后输出作为Reduce的输入,大体执行流程如下图所示: 整个流程图具体来说:每个...
MapReduce是一种云计算的核心计算模式,是一...流程图如下:数据被分割后通过Map函数将数据映射成不同的区块,分配给计算集群进行处理,以达到分布运算的效果,再通过Reduce函数将结果进行汇整,从而输出开发者所需...
一、MapReduce执行过程MapReduce运行时,首先通过Map读取HDFS中的数据,然后经过拆分,将每个文件中的每行数据分拆成键值对,最后输出作为Reduce的输入,大体执行流程如下图所示:整个流程图具体来说:每个Mapper...
1、分布式计算引擎的核心设计思路 分布式里的核心思路:...MapReduce:一句话讲就是分而治之+并行计算 HDFS:一句话总结,就是分散存储+冗余存储 但是,把单机计算程序,扩展成分布式计算应用程序,会遇到非常多的问
hadoop的MapReduce shuffle过程,非常重要。...MapReduce执行流程 输入和拆分: 不属于map和reduce的主要过程,但属于整个计算框架消耗时间的一部分,该部分会为正式的map准备数据。 分片(split)操作:...
推荐文章
- Java基础 高频面试题,2024年最新java多并发面试题-程序员宅基地
- vue视频播放插件vue-video-player的具体使用方法-程序员宅基地
- Element-UI 项目中 Pagination 分页如何使用 ???_element ui中pagination分页怎么用-程序员宅基地
- unity3dButton组件详细用法_unity button怎么用-程序员宅基地
- 安全***需要掌握的东西-程序员宅基地
- linux gs pdf,linux – 什么是汇编中的%gs-程序员宅基地
- 模拟退火算法matlab代码实现-程序员宅基地
- jQuery 语法实例_jquery-syntax示例-程序员宅基地
- Anaconda 安装与TensorFlow安装_error: pytest-astropy 0.8.0 requires pytest-cov>=2-程序员宅基地
- Assembly基础知识-程序员宅基地