PPO算法是一种强化学习中的策略梯度方法,它的全称是Proximal Policy Optimization,即近端策略优化1。PPO算法的目标是在与环境交互采样数据后,使用随机梯度上升优化一个“替代”目标函数,从而改进策略。PPO算法的...
”PPO“ 的搜索结果
根据OpenAI 提供的伪代码,PPO算法中的第一步。 受的简单实现启发,通过使用Actor和Critic网络创建轨迹

1. 背景介绍 1.1 强化学习的崛起 近年来,强化学习 (Reinforcement Learning, RL) 作为机器学习领域的一个重要分支,受到了越来越多的关注。它赋予了智能体在与环境交互的过程中学习和适应的能力,在游戏、机器人...
基于gym的pytorch深度强化学习实现源码+项目说明(PPO,DQN,SAC,DDPG,TD3等算法).zip 本人学习强化学习(PPO,DQN,SAC,DDPG等算法),在gym环境下写的代码集。 主要研究了PPO和DQN类算法,根据各个论文复现了如下改进: ...

PPO(Proximal Policy Optimization,近端策略优化)是一种强化学习算法,由John Schulman等人在2017年提出。PPO属于策略梯度方法,这类方法直接对策略(即模型的行为)进行优化,试图找到使得期望回报最大化的策略...
PPO初学者 介绍 你好! 我叫Eric Yu,我写了这个资料库来帮助初学者开始使用PyTorch从头开始编写近端策略优化(PPO)。 我的目标是为PPO提供一个基本的代码(很少/没有花哨的技巧),并提供充分的文档记录/样式和...
盆式PPO关于沉思-PPO 这是Pensieve [1]的一个简单的TensorFlow实现。 详细地说,我们通过PPO而非A3C培训了Pensieve。 这是一个稳定的版本,已经准备好训练集和测试集,并且您可以轻松运行仓库:只需键入python train...
PPO的简单学习笔记
1. 背景介绍 强化学习作为人工智能领域的重要分支,近年来取得了显著的进展。...PPO(Proximal Policy Optimization)算法作为策略梯度方法的一种,因其简单易用、稳定性强等优点,成为了强化学习领域的主流算法之一。
Proximal Policy Optimization (PPO) 是一种强化学习算法,用于训练能够执行连续动作的智能体,以最大化累积奖励。PPO是一种改进的策略梯度方法,旨在解决一些传统策略梯度方法的稳定性和样本效率问题。在本章的内容...
接着上面的讲,PG方法一个很大的缺点就是参数更新慢,因为我们每更新一次参数都需要进行重新的采样,这其实是中on-policy的策略,即我们想要训练的agent和与环境进行交互的agent是同一个agent;...
[PYTORCH]玩超级马里奥兄弟的近战策略优化(PPO) 介绍 这是我的python源代码,用于训练特工玩超级马里奥兄弟。 通过使用纸张近端策略优化算法推出近端政策优化(PPO)算法。 说到性能,我经过PPO培训的代理可以...
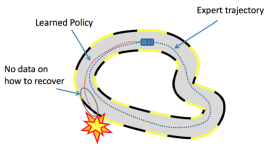
第一章:近端策略优化(PPO)算法原理详解 1. 背景介绍 1.1 强化学习与策略梯度方法 强化学习 (Reinforcement Learning, RL) 致力于让智能体在与环境的交互中学习到最优策略,从而最大化累积奖
随着大模型的飞速发展,在短短一年间就有了大幅度的技术迭代更新,从LoRA、QLoRA、AdaLoRa、ZeroQuant、Flash Attention、KTO、PPO、DPO、蒸馏技术到模型增量学习、数据处理、开源模型的理解等,几乎每天都有新的...
总结来说,PPO和DPO在算法框架和目标函数上有共同之处,但在实现方式、并行化程度以及适用的计算环境上存在差异,DPO特别适用于需要大规模并行处理的场景。总结来说,PPO专注于通过剪切概率比率来稳定策略更新,而...
0.引言PPO算法(Proximal Policy Optimization)是目前深度强化学习(DRL)领域,最广泛应用的算法之一。然而在实际应用的过程中,PPO算法的性能却受到多种因素的影响。本文总结了影响PPO算法性能的10个关键技巧,并通过...
PPO算法是由OpenAI提出的一种新的策略梯度算法,其实现复杂度远低于TRPO算法。PPO算法主要包括两种实现方法,第一种通过CPU仿真实现的,第二种通过GPU仿真实现的,其仿真速度是第一种PPO算法的三倍以上。此外,与...
基于pytorch深度强化学习的PPO,DQN,SAC,DDPG等算法实现python源码.zip基于pytorch深度强化学习的PPO,DQN,SAC,DDPG等算法实现python源码.zip基于pytorch深度强化学习的PPO,DQN,SAC,DDPG等算法实现python源码.zip基于...
PPO(Proximal Policy Optimization) 最好先看一下策略梯度优化,再看这篇文章,不然公式推不明白 PPO是Openai默认的强化学习策略 On-policy:学习的agent和与环境交互的agent是同一个 ∇Rˉθ=Eτ∼pθ(τ)[R(τ...
1. 背景介绍 1.1 对话式AI的兴起 随着人工智能技术的飞速发展,对话式AI(Conversational AI)已经成为近年来最热门的研究领域之一。从智能客服到虚拟助手,从聊天机器人到教育辅助工具,对话式AI正在逐渐改变着我们...

PPO算法之所以被提出,根本原因在于在处理连续动作空间时取值抉择困难。取值过小,就会导致深度强化学习收敛性较差,陷入完不成训练的局面,取值过大则导致新旧策略迭代时数据不一致,造成学习波动较大或局部震荡。...
基于李宏毅课程总结
[PYTORCH]针对矛盾的最近策略优化(PPO) 介绍 这是我的python源代码,用于训练代理播放相反的声音。 通过使用纸张近端策略优化算法推出近端政策优化(PPO)算法。 供您参考,PPO是OpenAI提出的算法,用于训练Open...
1. 背景介绍 1.1 强化学习与策略梯度方法 强化学习 (Reinforcement Learning, RL) 是机器学习的一个重要分支,它研究智能体 (agent) 如何在一个环境 (environment) 中通过与环境进行交互学习到最优策略 (policy),...
半猎豹(Half Cheetah)是一个基于MuJoCo的强化学习环境。
(1)在中国A股市场15只股票上的应用 (2)构建投资组合 (3)每日调仓 (4)绘制收益率曲线 (5)PPO算法
推荐文章
- withRouter,非根组件获取路由参数_withrouter 只能取到路由中的一个参数-程序员宅基地
- ubuntu环境下QT5操作摄像头报错,cannot find -lpulse-mainloop-glib cannot find -lpulse cannot find -lglib-2.0_cannot find–lpulse-程序员宅基地
- 用jbpm_bpel学jwsdp的ant方式使用-程序员宅基地
- 输入数字判断星期几_html获取当前星期几-程序员宅基地
- SpringBoot整合Activiti7——实战之放假流程(会签)_activit7中会签-程序员宅基地
- 阿里云服务器收到挖矿病毒的攻击,导致基础的文件被病毒污染的问题和对应的处理解决方法-程序员宅基地
- 北京东城区空调维修办法,格力变频空调出现ph,到底是怎么回事?_格力变频空调ph代码-程序员宅基地
- vscode编辑器使用拓展插件background添加背景图片改变外观_background vscode-程序员宅基地
- android 简单打电话程序_android拨打电话的程序-程序员宅基地
- 第二届中国(泰州)国际装备高层次人才创新创业大赛_泰州市双创人才计划2022-程序员宅基地