”SparkSql“ 的搜索结果

一:为什么sparkSQL? 3 1.1:sparkSQL的发展历程 3 1.1.1:hive and shark 3 1.1.2:Shark和sparkSQL 4 1.2:sparkSQL的性能 5 1.2.1:内存列存储(In-Memory Columnar Storage) 6 1.2.2:字节码生成技术...
1.1 什么是Spark SQL1Spark SQL是Spark用于结构化数据)处理的Spark模块。1.2 为什么要有Spark SQL。
(4)java程序实现SparkSQL 二、实验环境 Windows 10 VMware Workstation Pro虚拟机 Hadoop环境 Jdk1.8 三、实验内容 (一)SparkSQL的基本知识 (1)输入start-all.sh启动hadoop相应进程和相关的端口号 (2)启动...
本文介绍的是SparkSQL组件各个物理执行计划的操作实现。把优化后的逻辑执行计划映射到物理执行操作类这部分由SparkStrategies类实现,内部基于Catalyst提供的Strategy接口,实现了一些策略,用于分辨logicalPlan子类...
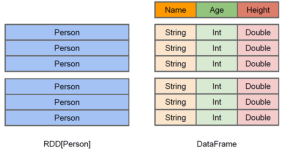
sparksql: Spark SQL是Spark处理数据的一个模块 专门用来处理结构化数据的模块,像json,parquet,avro,csv。 DataFrames API: 与RDD相似,增加了数据结构scheme描述信息部分。 比RDD更丰富的算子,更有利于...
sparksql: Spark SQL是Spark处理数据的一个模块 专门用来处理结构化数据的模块,像json,parquet,avro,csv,普通表格数据等均可。 与基础RDD的API不同,Spark SQL中提供的接口将提供给更多关于结构化数据和计算...
目录SparkSQL1. 基础概念2.DataFrame3.SparkSql程序开发(1.x,2.x)(1)SparkSQL1.x(2)SparkSQL2.x SparkSQL 1. 基础概念 Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且...
元数据库SparkSQL驱动程序依赖项构建JAR lein uberjar # builds target/metabase-sparksql-deps-1.2.1.spark2-standalone.jar签署JAR(可选) # (Replace keystore, TSA and profile below with your own)jarsigner ...
外部数据源API体现出的则是兼容并蓄,SparkSQL多元一体的结构化数据处理能力正在逐渐释放。关于作者:连城,Databricks工程师,Sparkcommitter,SparkSQL主要开发者之一。在4月18日召开的2015Spark技术峰会上,连城...
有赞数据平台从2017年上半年开始,逐步使用SparkSQL替代Hive执行离线任务,目前SparkSQL每天的运行作业数量5000个,占离线作业数目的55%,消耗的cpu资源占集群总资源的50%左右。本文介绍由SparkSQL替换Hive过程中...
一、案例介绍 案例包含三个表:tbDate、tbStock、tbStockDetail。字段信息如下表: 二、要求 1、计算所有订单中每年的销售单数、销售总额 2、计算所有订单每年最大金额订单的销售额 3、计算所有订单中每年最畅销...
Spark SQL是spark套件中一个模板,它将数据的计算任务通过SQL的形式转换成了RDD的计算,类似于Hive通过SQL的形式将数据的计算任务转换成了MapReduce。 Spark SQL的特点: 1、和Spark Core的无缝集成,可以在写整个...
1.SparkSQL概述 1.1.SparkSQL的前世今生 Shark是一个为Spark设计的大规模数据仓库系统,它与Hive兼容。Shark建立在Hive的代码基础上,并通过将Hive的部分物理执行计划交换出来。这个方法使得Shark的用户可以加速...
1.从HDFS中加载数据到DataFrame中 2.注册UDF函数,函数名为toUpper就是将所有名字变成大写 3.创建临时视图,然后执行注册的函数
本文讲述了Array、List、Map、本地磁盘文件、HDFS文件转化为DataFrame对象的方法;通过实际操作演示了dataFrame实例方法操作DataFrame对象、SQL语言操作DataFrame对象和ScalaAPI操作DataFrame对象
SparkSQL内置函数
SparkSQL通过Hive创建DataFrame问题分析 问题一 Caused by: org.apache.spark.sql.catalyst.analysis.NoSuchTableException: Table or view 'stu' not found in database 'default'; 分析:确实没有临时表View,...
ETL_with_Pyspark _-_ SparkSQL 一个示例项目,旨在使用Apache Spark中的Pyspark和Spark SQL API演示ETL过程。 在这个项目中,我使用了Apache Sparks的Pyspark和Spark SQL API来对数据实施ETL过程,最后将转换后的...
SparkSQL是Apache Spark的一个模块,用于处理结构化数据。它提供了一个DataFrame API来编写SQL查询,这些查询可以处理来自各种数据源的数据,并返回DataFrame作为结果。DataFrame是一个分布式的数据集合,可以包含...
6.SparkSQL(上)--SparkSQL简介.pdf 6.SparkSQL(下)--Spark实战应用.pdf 6.SparkSQL(中)--深入了解运行计划及调优.pdf 7.SparkStreaming(上)--SparkStreaming原理介绍.pdf 7.SparkStreaming(下)--Spark...
本篇文章要介绍的是–外连接查询中的谓词下推规则,这相比内连接中的规则要复杂一些,不过使用简单的表格来进行分析也是可以分析清楚的。先上表: 我们以左外 连 接查询为例,先总结规矩如下: ...
在当前企业生产数据膨胀的时代,数据即使企业的价值所在,也是一家企业的技术挑战所在。所以在海量数据处理场景上,人们意识到单机计算能力再强也无法满足日益增长的数据处理需求,分布式才是解决该类问题的根本解决...
SparkSQL详解
标签: spark
Spark SQL是 Spark 用来处理结构化数据的一个模块,它提供了 2 个编程抽象:DataFrame 和 DataSet,并且作为分布式 SQL 查询引擎的作用。
sparksql模型solr-poc POC在Solr中存储机器学习模型在hadoop生态系统的大多数技术部分(例如hive,spark等)中,推荐的存储机器学习模型的格式是木地板格式(由ASF开发)。 此POC试图在Solr中读取,解析并存储实木...

推荐文章
- Tensorflow for Java + Spark-Scala分布式机器学习计算框架的应用实践(1)-程序员宅基地
- 机器学习中训练集、验证集和测试集的作用_机器学习验证集-程序员宅基地
- picrust2功能预测-从qiime2安装到数据分析_picrust2功能预测结果怎么看-程序员宅基地
- C# Winform 窗体美化(二、LayeredSkin 界面库)-程序员宅基地
- Kanzi软件开发与Android的关系_kanzi_on_android_3_9_4_setup-程序员宅基地
- 【ChatGLM3】(7):在autodl上,使用A50显卡,使用LLaMa-Factory开源项目对ChatGLM3进行训练,非常方便的,也方便可以使用多个数据集_chatglm3 训练-程序员宅基地
- 高管内斗或使浆量下滑,海尔集团125亿元战投上海莱士存变数?_上海莱士 海尔-程序员宅基地
- ChatGPT AIGC 办公自动化拆分Excel工作表_ai 拆分excel-程序员宅基地
- 删除一个英文字符串当中所有的字母d C语言学习日志#3_编写程序,删除输入字符串中的字符d-程序员宅基地
- python实现接口上传文件的两种方法_python上传文件-程序员宅基地