1. 掌握 Spark SQL 的基本编程方法; 2. 熟悉 RDD 到 DataFrame 的转化方法; 3. 熟悉利用 Spark SQL 管理来自不同数据源的数据。
”SparkSql“ 的搜索结果
1.SparkSQL 整合 Hive 导读 开启Hive的MetaStore独立进程 整合SparkSQL和Hive的MetaStore 和一个文件格式不同,Hive是一个外部的数据存储和查询引擎, 所以如果Spark要访问Hive的话, 就需要先整合Hive ...
2.创建SparkSQL程序的SQL风格语法 运行结果: 3.创建SparkSQL程序的DSL风格语法 运行结果: 4.RDD转换DataFrame 运行结果: 5.DataFrame转换DataSet 运行结果: 6.DataFrame转换RDD ...
【Spark精讲】一文讲透SparkSQL执行过程,未解析的逻辑算子树,解析后的逻辑算子树,优化后的逻辑算子树,物理算子树,QueryPlan、LogicalPlan,SparkPlan,SparkSqlParser、AstBuilder、Analyzer、Optimizer
1.SparkSQL概述1.1.SparkSQL的前世今生Shark是一个为Spark设计的大规模数据仓库系统,它与Hive兼容。Shark建立在Hive的代码基础上,并通过将Hive的部分物理执行计划交换出来。这个方法使得Shark的用户可以加速Hive...
SparkSQL的前身是Shark,它抛弃原有Shark的代码,汲取了Shark的一些优点,如内存列存储(In-Memory Columnar Storage)、Hive兼容性等,重新开发了SparkSQL代码;由于摆脱了对Hive的依赖性,SparkSQL无论在数据兼容、性能...
Spark SQL是Spark用来处理结构化数据构建在SparkCore基础之上的一个基于SQL的计算模块。具有DSL和SQL两种查询方式。DSL:调用算子进行数据分析,对编程能力有要求。SQL:纯sql语句,使用之前,要将数据注册成为一张...
SparkSQL与Hive交互
sparkSQL.ipynb

尚硅谷大数据技术Spark教程-笔记08【SparkSQL(介绍、特点、数据模型、核心编程、案例实操、总结)】
IDEA开发SparkSQL 上一篇博客SparkSQL核心编程所有举的例子都是在虚拟机的命令行实现的,但是实际开发中,都是使用 IDEA 进行开发的,所以下面介绍下SparkSQL在IDEA中的使用。 准备工作 添加所需要的依赖(包括spark...
文章目录lnternalRow 体系数据源 RDD[lnternalRow]Shuffle ...SparkSQL在执行物理计划操作RDD时,会全部使用RDD<InternalRow>类型进行操作。 lnternalRow 体系 在SparkSQL 内部实现中, InternalRow 就是用来表示
本文介绍了SparkSQL如何支持Hive的访问。
sparksql: Spark SQL是Spark处理数据的一个模块 专门用来处理结构化数据的模块,像json,parquet,avro,csv,普通表格数据等均可。 与基础RDD的API不同,Spark SQL中提供的接口将提供给更多关于结构化数据和计算...
【代码】FlinkSQL和SparkSQL区别。
● 与基础 RDD(强类型,无结构) 的 API 不同,Spark SQL 中提供的接口将提供给更多关于结 构化数据和计算的信息,并针对这些信息,进行额外的处理优化。○rdd相比于df是缺少结构的,所以我们需要创建一个结构,给rdd...
自从去年SparkSubmit2013MichaelArmbrust分享了他的Catalyst,到至今1年多了,Spark SQL的贡献者从几人到了几十人,而且发展速度异常...前一段时间测试过Shark,并且对SparkSQL也进行了一些测试,但是还是忍不住对Spar


sparksql报错
标签: spark
拷贝hive的lib下的mysql-connector-java-5.1.46-bin.jar这个jar包到spark的jars下。因为spark与hive配置的Mysql作为元数据,需要对应的jar包依赖,缺少了mysql-connector的jar包。
文章目录SparkSQL操作hudi1、登录2、创建普通表3、创建分区表4、从现有表创建表5、用查询结果创建新表(CTAS)6、插入数据7、查询数据8、修改数据9、合并数据10、删除数据11、覆盖写入12、修改数据表13、hudi分区命令 ...
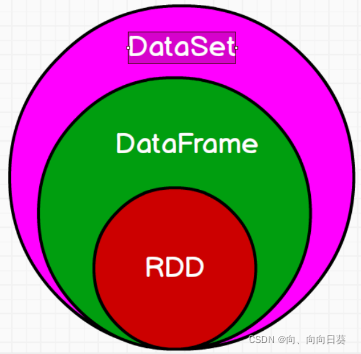
外部数据源API体现出的则是兼容并蓄,SparkSQL多元一体的结构化数据处理能力正在逐渐释放。关于作者:连城,Databricks工程师,Sparkcommitter,SparkSQL主要开发者之一。在4月18日召开的2015Spark技术峰会上,连城...
NULL 博文链接:https://humingminghz.iteye.com/blog/2309413
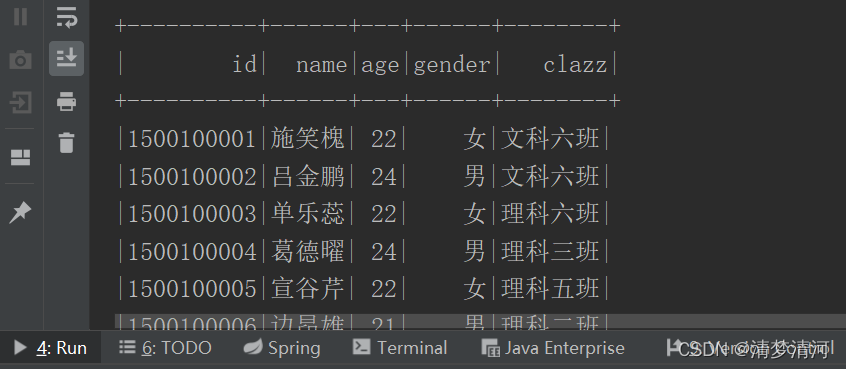
sparksql不复杂,只要创建好了DataFrame(泛型为RDD的DataSet),然后通过这个df创建个临时表然后写sql,就能用我们的sqark计算框架做一些我们想要的计算了,而且是只要写sql哦!是不是很好用,只要会sql!就能用!...

推荐文章
- Android RIL框架分析-程序员宅基地
- Python编程基础:第六节 math包的基础使用Math Functions_ps math function-程序员宅基地
- canal异常 Could not find first log file name in binary log index file_canal could not find first log file name in binary-程序员宅基地
- 【练习】生成10个1到20之间的不重复的随机数并降序输出-程序员宅基地
- linux系统扩展名大全,Linux系统文件扩展名学习-程序员宅基地
- WPF TabControl 滚动选项卡_wpf 使用tabcontrol如何给切换的页面增加滚动条-程序员宅基地
- Apache Jmeter常用插件下载及安装及软硬件性能指标_jmeter插件下载-程序员宅基地
- SpringBoot 2.X整合Mybatis_springboot2.1.5整合mybatis不需要配置mapper-locations-程序员宅基地
- ios刷android8.0,颤抖吧 iOS, Android 8.0正式发布!-程序员宅基地
- 【halcon】C# halcon 内存暴增_halcon 读二维码占内存-程序员宅基地