1.SparkSQL概述1.1.SparkSQL的前世今生Shark是一个为Spark设计的大规模数据仓库系统,它与Hive兼容。Shark建立在Hive的代码基础上,并通过将Hive的部分物理执行计划交换出来。这个方法使得Shark的用户可以加速Hive...
”Spark计算引擎之SparkSQL详解“ 的搜索结果
Spark学习笔记 一、Spark基本概念 1、架构初析 1-1、Spark的基本架构组成 Spark应用程序由一个驱动器进程(driver)和一组执行器(worker)进程组成。 其中驱动器(driver)的作用是:维护Spark应用程序的相关信息;...

SparkSQL详解
标签: spark
Spark SQL是 Spark 用来处理结构化数据的一个模块,它提供了 2 个编程抽象:DataFrame 和 DataSet,并且作为分布式 SQL 查询引擎的作用。


在本篇文章中,笔者将给大家带来 Spark SQL 中关于自适应执行引擎(Spark Adaptive Execution)的内容。 在之前的文章中,笔者介绍过 Flink SQL,目前 Flink 社区在积极地更新迭代 Flink SQL 功能和优化性能,尤其 ...
它旨在执行批处理(类似于MapReduce)和提供新的工作特性,例如流计算,SparkSQL交互式查询和Machine Learning机器学习等。 我的数据需要容纳在内存中才能使用Spark吗? 不会。Spark的operators会在不适合内存的情况下...
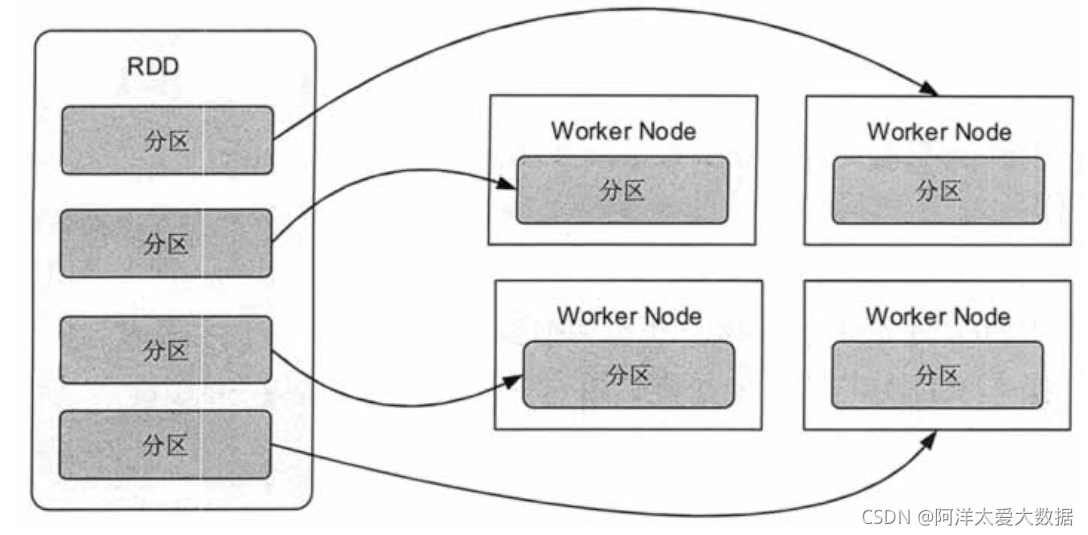


文章目录前言一、Spark运行1.1核心组件1.2运行流程1.3集群部署模式1.4yarn模式运行机制1.5Spark RPC框架二、SparkContext2.1SparkContext...详解4.1Spark Shuffle的两个阶段4.2Spark Shuffle技术演进4.3Hash Shuffle...
目录一、Spark SQL概念二、Spark SQL功能三、Spark SQL 与 Hive 的区别 一、Spark SQL概念 它主要用于结构化数据处理和对Spark数据执行类SQL的查询。通过Spark SQL,可以针对不同格式的数据执行ETL操作(如JSON,...

本文主要从以下几个方面介绍SparkStreaming: 一、SparkStreaming是什么 二、SparkStreaming支持的业务场景 三、SparkStreaming的相关概念 四、DStream介绍 五、SparkStreaming的机制 六、SparkStreaming的Demo...

sparkSQL实战详解
标签: spark
如果要想真正的掌握sparkSQL编程,首先要对sparkSQL的整体框架以及sparkSQL到底能帮助我们解决什么问题有一个整体的认识,然后就是对各个层级关系有一个清晰的认识后,才能真正的掌握它,对于sparkSQL整体框架这一块...

Spark RDD详解 Spark 常用算子大全 Spark SQL 详解 Spark SQLspark 系列前言Spark SQL 简介什么是Spark SQL?Spark SQL 的由来Spark SQL 的特点Spark SQL 框架结构Spark SQL的核心 Catalyst优化器(了解)Spark SQL...
一 Spark概述 1 11 什么是Spark 2 Spark特点 3 Spark的用户和用途 二 Spark集群安装 1 集群角色 2 机器准备 3 下载Spark安装包 4 配置SparkStandalone 5 配置Job History ServerStandalone 6 ...
如今Spark SQL(Dataset/DataFrame)已经成为Spark应用程序开发的主流,作为开发者,我们有必要了解Join在Spark中是如何组织运行的。 2. Join的基本要素 如下图所示,Join大致包括三个要素:Join方

SparkSQL详解,底层原理,执行过程,参数调优
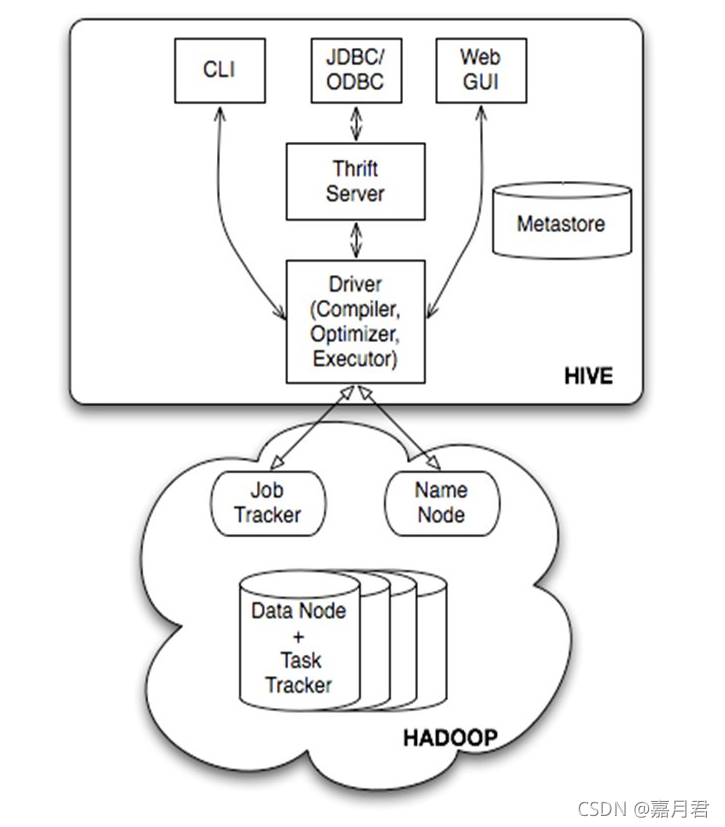

推荐文章
- Android RIL框架分析-程序员宅基地
- Python编程基础:第六节 math包的基础使用Math Functions_ps math function-程序员宅基地
- canal异常 Could not find first log file name in binary log index file_canal could not find first log file name in binary-程序员宅基地
- 【练习】生成10个1到20之间的不重复的随机数并降序输出-程序员宅基地
- linux系统扩展名大全,Linux系统文件扩展名学习-程序员宅基地
- WPF TabControl 滚动选项卡_wpf 使用tabcontrol如何给切换的页面增加滚动条-程序员宅基地
- Apache Jmeter常用插件下载及安装及软硬件性能指标_jmeter插件下载-程序员宅基地
- SpringBoot 2.X整合Mybatis_springboot2.1.5整合mybatis不需要配置mapper-locations-程序员宅基地
- ios刷android8.0,颤抖吧 iOS, Android 8.0正式发布!-程序员宅基地
- 【halcon】C# halcon 内存暴增_halcon 读二维码占内存-程序员宅基地