深度学习 1. 训练框架: Google的TensorFlow:项目部署落地 FaceBook的Pytorch:易用性 另外亚马逊的MxNet 百度的Paddle 旷视的MegEngine 华为的Mindspore 一流科技的OneFlow:分布式训练最快 无论选择何...
”TVM深度学习编译器“ 的搜索结果

这一篇文章将继续介绍一下TVM的编译流程,即TVM是如何将深度学习框架的模型转换成Relay IR之后进一步编译和优化为硬件可以执行的IR,再将这个底层IR和运行时库以及模型参数打包为一个tvm.Module返回。关于为什么要将...


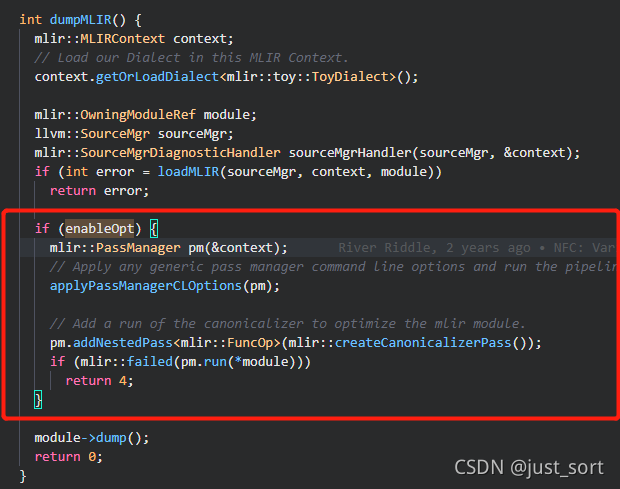
在【从零开始学深度学习编译器】五,TVM Relay以及Pass简介 这篇推文中已经简单介绍了Relay和Pass机制。但是那篇文章介绍得不是很细节,对Relay的抽象语法树结构以及Pass的代码实现都没有细读,因此这篇文章以...
陈天奇给了关于TVM的报告,TVM: An End to End Automated Deep Learning Compiler。 文件:n459.com/file/25127180-479068743 以下内容无关: -------------------------------------------分割线------------------...


深度学习编译器TVM安装
标签: 机器学习
这里写自定义目录标题前言下载TVM源代码安装g++和cmake构建共享库插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注脚...
为了解决DL库和工具的缺点,减轻手动优化每个DL硬件上的DL模型的负担,DL社区正在促进特定领域的编译器的发展。此外,现有的DL编译器还利用了来自通用编译器(例如LLVM)的成熟工具链,这在不同的硬件架构中提供了更...
更多的深度学习编译器知识可以在 https://github.com/BBuf/tvm_mlir_learn 找到。同时也维护了一个cuda学习仓库 https://github.com/BBuf/how-to-optim-algorithm-in-cuda 以及一个如何学习深度学习框架(PyTorch和...
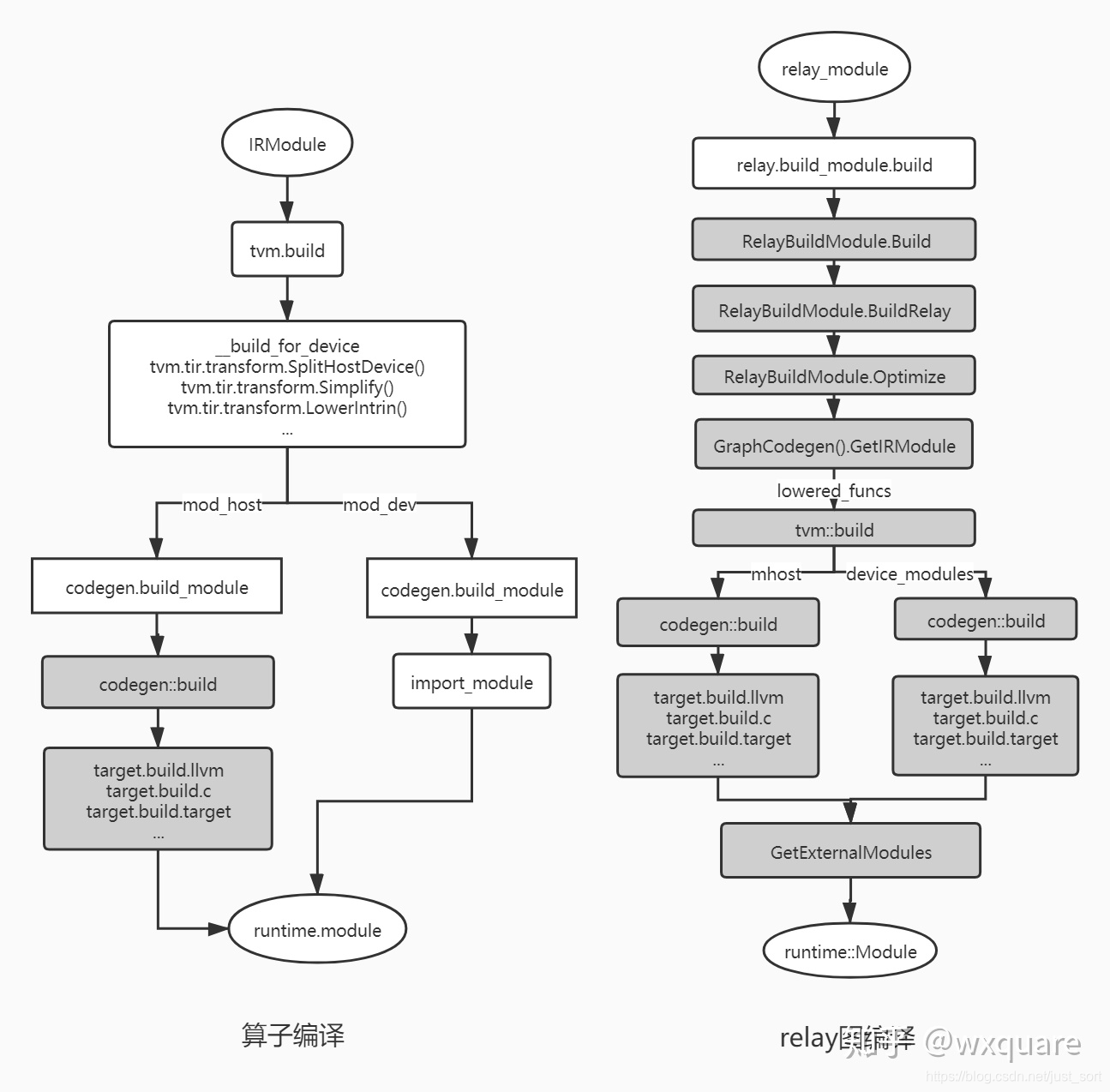
在【从零开始学深度学习编译器】一,深度学习编译器及TVM 介绍我们已经知道TVM可以将各种深度学习训练框架的模型(计算图)导入Relay,然后调用build接口自动生成target代码如c,llvm等。在深度学习编译器中,自动...


作者 | 小O妹出品 |AI科技大本营(ID:rgznai100)神经网络编译器概览近年来,以机器学习、深度学习为核心的AI技术得到迅猛发展,深度神经网络在各行各业得到广泛应用:1. ...
TVM所做的是要比传统compiler更偏上层的,你可以把它理解成source-to-source compiler,需要其他的后端(backend)来生成最后的指令。比如当编译的Target是Intel CPU时,翻译的顺序是Relay IR -> TVM IR/ Halide IR ->...
在【从零开始学深度学习编译器】一,深度学习编译器及TVM 介绍我们已经知道TVM可以将各种深度学习训练框架的模型(计算图)转化为内部的Graph IR(Relay),然后通过TVM提供的指令生成模块将Graph IR翻译成特定硬件...
不报错并显示对应的库目录路径意味着前面的步骤都完成了,下面就开始搭建TVM。这个步骤也要等待蛮久的,大概半小时(而且非常占用CPU,电脑风扇起飞),接下来是编译LLVM,简便行事我们可以使用已经手动编译好的库,...

最近在基于深度学习编译器做一些开发,这里记录一下学习历程首先讲述一下我们最常接触到的训练框架,其中已经内含了深度学习编译器,而深度学习编译系统则包括深度学习框架与其它工具,提供全面的深度学习解决方案。
Apache TVM 是一个开放源代码的机器学习编译器框架,用于 CPU,GPU 和机器学习加速器。Apache TVM 是深度学习系统的编译器栈。它旨在缩小注重生产力的深度学习框架与注重性能和效率的硬件后端之间的差距。TVM 与深度...
编译器前端将用户代码解析得到计算图 IR,并且做了一些和计算设备无关的通用优化。编译器后端做的优化就和具体的设备有关了(不同设备有不同的 allocator,不同的编程模型,比如英伟达的 CUDA),后端优化更加贴合...
推荐文章
- 解决syszuxpinyin重复点击lineEdit无法弹出输入法界面和无法删除原有内容问题_qlineedit输入中文无法删除-程序员宅基地
- jeb 下载-程序员宅基地
- python绿色参数_Python进阶三部曲之IO操作-程序员宅基地
- 高通平台8953 Linux DTS(Device Tree Source)设备树详解之一(背景基础知识篇)_高通提取dtb-程序员宅基地
- ubuntu上opencv源码编译_libjasper-dev源码-程序员宅基地
- 安卓设备连接Unity Profiler进行性能分析_unity profile 手机-程序员宅基地
- 学习一下windows系统的的目录结构,对比一下Linux系统的目录结构_windows内置linux目录结构-程序员宅基地
- 海思3559AV100实现8k文件编码_rk_mpi_cal_comm_getpicbuffersize-程序员宅基地
- Android BLE 蓝牙通信库,2024年最新应届生面试销售岗位的面试问题技巧_android蓝牙通信-程序员宅基地
- vue el-input表单验证禁止输入空格_element表单空格校验-程序员宅基地