”offset“ 的搜索结果
kafka的offset理解 kafka是顺序读写,具备很好的吞吐量。实现原理是 每次生产消息时,都是往对应partition的文件中追加写入,而消息的被读取状态是由consumer来维护的 所以每个partition中offset一般都是连续递增的...
可以继续读取并消费下一批消息。注意,该计算的数值是理想i情况下的理论数值,在生产环境中,不建议直接使用,而是根据当前环境,先设置一个比该值小的数值然后观察其压测效果,然后再根据效果逐步调大线程数,直到...
这个函数用沿面法线的一定距离来偏移一个区域。
1 问题背景 在使用Kafka消费数据过程中,消费程序可能出现运行问题,导致消费不及时,消息堆积很多;尤其是消息消费后需要进行一列后处理,这种情况下就需要考虑一些方法来进行消费参数的设置。...
产生偏移。
消费组和偏移量的关系
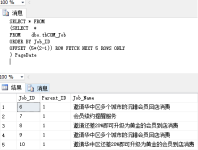
在Kafka Version为...
【代码】unity 动态修改material offset偏移量。
offset系列常用属性**注意:1.element.offsetTop及element.offsetLeft以带有定位的父亲为准,如果没有父亲或者父亲没有定位则以body为准2.element.offsetWidth和element.offsetHeight 返回的宽度及高度是带padding值...
可以修改IP,或同时修改CS和IP的指令统称为转移指令。概括的讲,转移指令就是可以控制CPU执行内存中某处代码的指令。
文章目录官方说明参数解读 官方说明 https://kafka.apache.org/documentation/ 选择对应的版本,我这里选的是 2.4.X ...选择 ...查找 auto.offset.reset 参数解读 ...

假如现在有 7 个分区,3 个消费者,排序后的分区将会 是0,1,2,3,4,5,6;RoundRobin 轮询分区策略,是把所有的 partition 和所有的 consumer 都列出来,然后按照 hashcode 进行排序,最后 通过轮询算法来分配 ...
= width+左右padding+左右border= height+上下padding+上下border= 距离左侧浏览器的横坐标= 距离上侧浏览器的纵坐标= 距离左侧父元素的横坐标= 距离上侧父元素的纵坐标。
【代码】compact unwind compressed function offset doesn‘t fit in 24 bits。
有的时候我们在学习或者工作中会使用到SQL语句,那么介绍一下limit和offset的使用方法。 mysql里分页一般用limit来实现,例如: 1、select* from user limit 3 表示直接取前三条数据 2、select * from user limit 1,...
总结来说,面试成功=基础知识+项目经验+表达技巧+运气。我们无法控制运气,但是我们可以在别的地方花更多时间,每个环节都提前做好准备。面试一方面是为了找到工作,升职加薪,另一方面也是对于自我能力的考察。...
别再用 offset 和 limit 分页了,性能太差!
mysql offset用法
标签: mysql
SQL查询语句中的 limit 与 offset 的区别: limit y 分句表示: 读取 y 条数据 limit x, y 分句表示: 跳过 x 条数据,读取 y 条数据 limit y offset x 分句表示: 跳过 x 条数据,读取 y 条数据
I was googling and reading Kafka documentation but I couldn’t find out the max value of a consumer offset and whether there is offset wraparound after max value. I understand offset is an Int64 value...
Spark整合Kafka两种模式说明 开发中我们经常会利用SparkStreaming实时地读取kafka中的数据然后进行处理,在Spark1.3版本后,KafkaUtils里面提供了两种创建DStream的方法: 1.Receiver接收方式:KafkaUtils....
今天给大家介绍一下TOP、OFFSET-FETCH、SET ROWCOUNT用法笔记,希望对大家能有所帮助!1、 TOP用法语法格式:TOP ( expression ) [ PERCEN...
Kafka将数据持久化到了硬盘上,允许你配置一定的策略对数据清理,清理的策略有两个,删除和压缩。数据清理的方式删除log.cleanup.policy=delete启用删除策略直接删除,删除后的消息不可恢复。可配置以下两个策略:...

oracle rownum 用法与pgsql limit offset用法

offset: 一个连续的用于定位被追加到分区的每一个消息的***,最大值为64位的long大小,19位数字字符长度。 理解为类比Java中的数组,kafka里面存着消息的数组,offset类似于数组下标。Kafka与其它队列的一个区别是...
有些数据传输只能传输正整数,负物理量就需要偏移量转换成正整数传输。例如:0.1V/bit、1℃/bit、0.05A/bit等。...a是分辨率(factor)b是偏移量(offset)a是分辨率(factor)b是偏移量(offset)偏移量(offset)
推荐文章
- Pytorch Dataloader 模块源码分析(二):Sampler / Fetcher 组件及 Dataloader 核心代码-程序员宅基地
- Asp类型判断及数组打印-程序员宅基地
- Adroid Studio 2022.3.1 版本配置greendao提示无法找到_plugin with id 'org.greenrobot.greendao' not found-程序员宅基地
- esxi查看许可过期_解决Vsphere Client 60天过期问题-程序员宅基地
- CMake_cmake_module_path-程序员宅基地
- 生产者消费者模型-程序员宅基地
- Adaptive AUTOSAR 解决方案 INTEWORK-EAS-AP_autosar的eas-程序员宅基地
- 穿山甲SDK错误码40025_穿山甲sdk错误码4025-程序员宅基地
- css firefox下的兼容问题_css 只用于firefox-程序员宅基地
- 【Python】对大数质因数分解的算法问题_python分解多个质因数代码-程序员宅基地