无
”python中utf-8编码“ 的搜索结果
python烟花代码-02-获取标签元素.ev4.rar
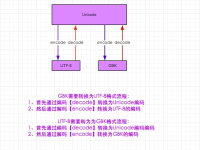
通俗的说,按照何种规则将字符存储在计算机中,如’a’用什么表示,称为"编码";反之,将存储在计算机中的二进制数解析显示出来,称为"解码",如同密码学中的加密和解密。在解码过程中,如果使用了错误的解码规则,...
字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。 decode的作用是将其他...

主要介绍了Python利用 utf-8-sig 编码格式解决写入 csv 文件乱码问题,本文给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下
一般我喜欢用 utf-8 编码,在 python 怎么使用呢?1、在 python 源码文件中用 utf-8 文字。一般会报错,如下:File "F:\workspace\psh\src\test.py", line 2 SyntaxError: Non-ASCII character '\xe4' in file F:\...
那小编开始提问了,utf-8编码如何转换?有的小伙伴可能对这个词模模糊糊的有点印象。但是如果我们提到unicode编码大家就会觉得很熟悉。所以今天讲的是unicode编码里的utf-8,大家一起来试试两个不同编码的区别吧,...
该文件是用于Unicode字符的UTF-8编码文件。 我想打印前10个UTF-8字符,但是下面代码片段的输出显示了10个无法识别的怪异字符。 想知道是否有人对如何正确打印有任何想法? 谢谢。with open(name, 'r') as content_...
基本概念在Python里有两种类型的字符串类型:字节字符串和...在Mac OX上默认的编码是UTF-8,但是在别的系统上,大部分是ASCII。比如创建一个字节字符串:byteString = "hello world! (in my default locale)"创建...
当使用Python编程时,编码问题一直很让人头疼,程序中经常会碰到如下错误提示:UnicodeDecodeError: 'ascii' codec can't decode byte 0x?? in position 1: ordinal not in range(128)这是由于python在安装时,默认...
#UTF-8转换成GBK编码#temp#decode#encode#原理就是把UTF-8转换成万国码,再给万国码进行编码转换成GBK,在python 2.x里面这么用"""给变量temp赋值等于’李杰‘是UTF-8编码!变量temp_unicode的赋值等于temp变量的...
Python中默认的编码格式是ASCII格式,在没修改编码格式时无法正确打印汉字,所以在读取中文时会报错。 解决方法为只要在文件开头加入 # -*- coding: UTF-8 -*-...注意:Python3.X 源码文件默认使用utf-8编码,所以可以
python 使用 UTF-8 编码
1,UTF-8在python的开始处,#coding:utf-8或者#coding=utf-8的作用一样,声明Python代码的文本格式是UTF-8,按照这种格式来读取程序。如下编写一个脚本:如果不添加#coding=utf-8,脚本有中文时程序会报错2,Unicode和...
UTF-8(8位元,Universal Character Set/Unicode Transformation Format)是针对Unicode的一种可变长度字符编码。它可以用来表示Unicode标准中的任何字符,而且其编码中的第一个字节仍与ASCII相容,使得原来处理...
本文实例讲述了python实现unicode转中文及转换默认编码的方法。分享给大家供大家参考,具体如下:一、在爬虫抓取网页信息时常需要将类似"\u4eba\u751f\u82e6\u77ed\uff0cpy\u662f\u5cb8"转换为中文,实际上这是...
展开全部概述在2113python代码即.py文件的头部声明即可解析5261py文件中的编码Python 默认脚本文件都是 ANSCII 编码的,当4102文件 中有非 ANSCII 编码范围内的字符的时候就要使用"编码指示"来修正一个 module的定义...
json文件读取成dataframe出现了yurf-8编码错误
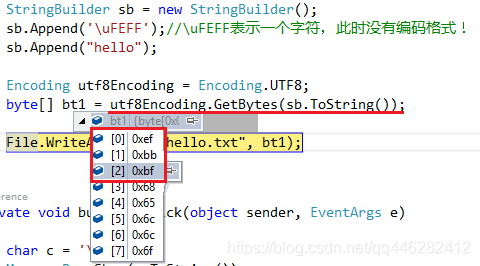
当使用Python编程时,编码问题一直很让人头疼,程序中经常会碰到如下错误提示:UnicodeDecodeError: 'ascii' codec can't decode byte 0x?? in position 1: ordinal not in range(128)这是由于python在安装时,默认...
当我这样做的时候:file = codecs.open("temp","w","utf-8")file.write(codecs.BOM_UTF8)file.close()它给了我错误UnicodeDecodeError: 'ascii' codec can't decode byte 0xef in position0: ordinal n...

主要介绍了Python3读取UTF-8文件及统计文件行数的方法,涉及Python读取指定编码文件的相关技巧,需要的朋友可以参考下
在Mac OX上默认的编码是UTF-8,但是在别的系统上,大部分是ASCII。 比如创建一个字节字符串: byteString = "hello world! (in my default locale)" 创建一个Unicode字符串: unicodeString = u"hello Unico
在Python中,我们可以使用encode()和decode()函数进行字符串的编码转换,其中,UTF-8编码是一种常用的编码方式,需要我们掌握其转换方法。在代码中,我们首先定义了一个UTF-8编码的字符串str1,然后使用decode()函数...
一般我喜欢用 utf-8 编码,在 python 怎么使用呢? 使用utf-8 文字 在 python 源码文件中用 utf-8 文字。一般会报错,如下: File "F:\workspace\psh\src\test.py", line 2 SyntaxError: Non-ASCII character...
抓不住i回答时间:2019-12-05向TA提问重装了系统(ubuntu 14.04)原来正常可用的OpenERP项目在切换到开发者模式的... in position 1: ordinal not in range(128)而在服务器上的项目正常可用,其原因是由于python的默认...
推荐文章
- YOLO V8车辆行人识别_yolov8 无法识别路边行人-程序员宅基地
- jpa mysql分页_Spring Boot之JPA分页-程序员宅基地
- win10打印图片中间空白以及选择打印机预览重启_win10更新后打印图片中间空白-程序员宅基地
- 【加密】SHA256加盐加密_sha256随机盐加密-程序员宅基地
- cordys 启动流程_cordys服务重启-程序员宅基地
- net中 DLL、GAC-程序员宅基地
- (一看就会)Visual Studio设置字体大小_visual studio怎么调整字体大小-程序员宅基地
- Linux中如何读写硬盘(或Virtual Disk)上指定物理扇区_dd写入确定扇区-程序员宅基地
- python【力扣LeetCode算法题库】面试题 17.16- 按摩师(DP)_一个有名的讲师,预约一小时为单位,每次预约服务之间要有休息时间,给定一个预约请-程序员宅基地
- 进制的转换技巧_10111100b转换为十进制-程序员宅基地