
”python的groupby中函数详解“ 的搜索结果
python标准库包含于日期(date)和时间(time)数据的数据类型,datetime、time以及calendar模块会被经常用到。datetime以毫秒形式存储日期和时间,datetime.timedelta表示两个datetime对象之间的时间差。下面我们先简单...
GroupBy group_by的底层步骤: (1)split:依据某个标准把数据 分割 (2)Apply:将某个函数 应用 到每一组数据,例如agg、transform (3)combining:将结果合并 在apply这一步,我们可以采取: (1)聚合操作:将...

在建模过程中,我们常常需要需要对有时间关系的数据进行整理。比如我们想要得到某一时刻过去30分钟的销量(产量,速度,消耗量等),传统方法复杂消耗资源较多,pandas提供的rolling使用简单,速度较快。函数原型和...
最近在工作上用到Python的pandas库来处理excel文件,遇到列转行的问题。找了一番资料后成功了,记录一下。1. 如果需要爆炸的只有一列:df=pd.DataFrame({"A":[1,2],"B":[[1,2],[1,2]]})dfOut[1]:A B0 1 [1, 2]1 2 [1...
pandas groupby comcount()详解
Python中的正则表达式方面的功能,很强大。 其中就包括re.sub,实现正则的替换。 功能很强大,所以导致用法稍微有点复杂。 所以当遇到稍微复杂的用法时候,就容易犯错。 所以此处,总结一下,在使用re.sub的时候,...
官方函数DataFrame.locAccess a group of rows and columns by label(s) or a boolean array..loc[] is primarily label based, but may also be used with a boolean array.# 可以使用label值,但是也可以使用布尔...
本文研究的主要是pandas常用函数,具体介绍如下。 1 import语句 1 2 3 4 5 import pandas as pd import numpy as np import matplotlib.pyplot as plt import ...

简单介绍Python中的len()函数的使用函数:len()1:作用:返回字符串、列表、字典、元组等长度2:语法:len(str)3:参数:str:要计算的字符串、列表、字典、元组等4:返回值:字符串、列表、字典、元组等元素的长度5...
下表展示了优化的groupby方法。可以使用自行制定的聚合,并再调用已经在分组对象上定义好的方法。尽管quantile并不是显式地为GroupBy对象实现的,但它是Series的方法,因此也可以用于聚合。在内部,GroupBy有效地对...
通过调用循环器的next()方法 (next()方法,在Python 3.x中),循环器将依次返回一个对象。直到所有的对象遍历穷尽,循环器将举出StopIteration错误。在for i in iterator结构中,循环器每次返回的对象将赋予给i,直到...

最近在工作上用到Python的pandas库来处理excel文件,遇到列转行的问题。找了一番资料后成功了,记录一下。1. 如果需要爆炸的只有一列:df=pd.DataFrame({'A':[1,2],'B':[[1,2],[1,2]]})dfOut[1]:A B0 1 [1, 2]1 2 [1...
Access a group of rows and columns by label(s) or a boolean array. .loc[] is primarily label based, but may also be used with a boolean array. # 可以使用label值,但是也可以使用布尔值 Allowed inputs ...
目录简介无穷迭代器count()cycle()repeat()有限迭代器chain()groupby()accumulate()组合迭代器product()permutations()combinations()combinations_with_replacement() 简介 itertools,是python的一个内置模块,...
1.自定义聚合函数,结合agg使用2. 同时使用多个聚合函数3. 指定某一列使用某些聚合函数4.merge与transform使用import pandas as pdimport numpy as npnp.random.seed(1)dict_data = {"k1": ["a", "b", "c", "d", "a...

在建模过程中,我们常常需要需要对有时间关系的数据进行整理。比如我们想要得到某一时刻过去30分钟的销量(产量,速度,消耗量等),传统方法复杂消耗资源较多,pandas提供的rolling使用简单,速度较快。函数原型和...
通过调用循环器的next()方法 (next()方法,在Python 3.x中),循环器将依次返回一个对象。直到所有的对象遍历穷尽,循环器将举出StopIteration错误。在for i in iterator结构中,循环器每次返回的对象将赋予给i,直到...
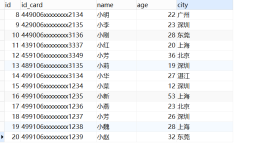
Groupby详解 在日常的数据分析中,经常需要将数据根据某个(多个)字段划分为不同的群体(group)进行分析,如电商领域将全国的总销售额根据省份进行划分,分析各省销售额的变化情况,社交领域将用户根据画像...
pandas.DataFrame.groupby() Group DataFrame using a mapper or by a Series of columns. A groupby operation involves some combination of splitting the object, applying a function, and combining the ...
1.在python DTL模板中,想要定义变量,可以通过“with”语句来实现。2.“with”语句有两种使用方式:第一种是“with xx=xx”的形式,注意,使用这种形式进行定义变量的话,=号两边不能有空格,否则的话,DTL模板就会...
讲解python的分页器之前,科普一下java的分页器每门编程语言都有一个分页的工具,类似java有PageHelper分页插件Mybatis从入门到精通(全)米米商城项目实战(含项目源码)而Paginator是Django的一个分页工具,通过...
然后,我们使用`groupby`函数对数据按照性别进行分组。最后,我们使用`agg`函数对分组后的数据进行聚合操作,计算每个性别的年龄的均值和标准差,以及分数的最大值。 在`agg`函数的参数中,我们使用字典来指定每个...
推荐文章
- spring boot>>RabbitMQ中间件发送验证码_basevo依赖-程序员宅基地
- uiautomatorviewer拉取手机竖屏却显示为横屏的问题_uiautomatorviewer方向倒了-程序员宅基地
- 加密技术简介-程序员宅基地
- 使用迭代器Iterator遍历Collection_.keyset().iterator().next()-程序员宅基地
- 日常Java练习题(每天进步一点点系列)_callable的call方法返回值-程序员宅基地
- 已解决Using TensorFlow backend.-程序员宅基地
- ring0下的 fs:[124]_nsfs124-程序员宅基地
- 高德地图打包后不能使用,高德导航View不显示,高德地图导航组件黑屏的问题;_amap.amapwx打包成安卓后无法使用-程序员宅基地
- HTML5与微信开发(2)-视频播放事件及API属性_微信开发者工具视频快进-程序员宅基地
- JedisConnectionException Connection Reset_jedisconnectionexception: java.net.socketexception-程序员宅基地