大数据~有关于RDD编程初级实践的学习报告 小丸子帮大家总结到位了 希望可以帮助各位 点赞收藏哈!!!
”rdd“ 的搜索结果
Partition 类内包含一个 index 成员,表示该分区在 RDD 内的编号,通过 RDD 编号 + 分区编号可以唯一确定该分区对应的块编号,利用底层数据存储层提供的接口,就能从存储介质(如:HDFS、Memory)中提取出分区对应的数据。...
Rdd的支持两种类型的算子操作,一类是Transformations,一类是Action算子。本文以代码结合文字的形式最全面,最详细的总结了Spark中的各类算子的操作。
DDIT_RDD_出口退税申报系统安装环境注意事项及常见问题_龙图信息_20131225.docxDDIT_RDD_出口退税申报系统安装环境注意事项及常见问题_龙图信息_20131225.docxDDIT_RDD_出口退税申报系统安装环境注意事项及常见问题_...
DDIT_RDD_出口退税申报系统安装环境注意事项及常见问题_龙图信息_20131225.pdfDDIT_RDD_出口退税申报系统安装环境注意事项及常见问题_龙图信息_20131225.pdfDDIT_RDD_出口退税申报系统安装环境注意事项及常见问题_...


从sortBy函数的实现可以看出,第一个参数是必须传入的,而后面的两个参数可以不传入.而且sortBy函数函数的实现依赖于skeyBy和sortByKey函数,后面会进行说明
数据读取 hadoopFile Parameters: path – path to Hadoop file inputFormatClass – fully qualified classname of Hadoop InputFormat (e.g. “org.apache.hadoop.mapred....keyClass – fully qualified ...
aggregate(zeroValue, seqOp, combOp) 入参: zeroValue表示一组初值 Tuple ...聚合后的结果,不是RDD,是一个python对象 下面是对一组数进行累加,并计算数据的长度的例子 # sum, sum1, sum2 的数据类型跟zeroV
Rdd Ticker-crx插件
标签: 扩展程序
此扩展显示当前的RDD / BTC价格徽章。 rdd ticker - 显示工具栏上的Redd硬币的当前BTC价格(价格从Cryptsy API检索) 每2分钟进行自动更新价格 点击更新价格按需 如果你喜欢皇室,请随意提示我 BTC - 1E2...
1 RDD的数据结构模型 前言:自Google发表三大论文GFS、MapReduce、BigTable以来,衍生出的开源框架越来越多,其中Hadoop更是以高可用、高扩展、高容错等特性形成了开源工业界事实标准。Hadoop是一个可以搭建在廉价PC...

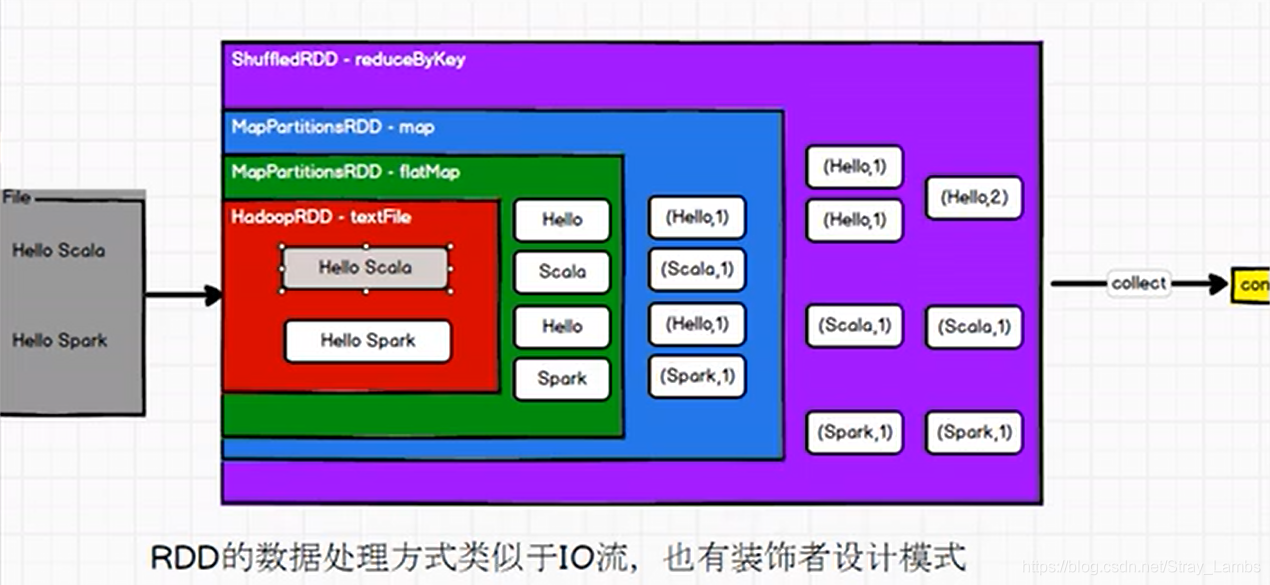
Note of rdd
PPT+RDD
RDD的创建 头歌答案
spark 之如何创建空的RDD 1 创建没有分区的空 RDD 在 Spark 中,对 SparkContext 对象使用 emptyRDD() 函数会创建一个没有分区或元素的空 RDD。 下面的示例创建一个空 RDD。 In Spark, using emptyRDD() function ...
PySpark的RDD介绍

RDD提供了一组非常丰富的操作来操作数据,如:map,flatMap,filter等转换操作,以及SaveAsTextFile,conutByKey等行动操作。这里仅仅综述了转换操作。 map map是对RDD中的每一个元素都执行一个指定的函数来产生一个新...

Python Spark RDD 创建RDD # 从本地文件加载 stringRDD = sc.textFile("file:/usr/local/spark/README.md") # 从HDFS加载 stringRDD = sc.textFile("hdfs://master:9000/user/hduser/input/test.txt") # 通过并行...

RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。这里的弹性指的是RDD可以根据当前情况自动进行内存和硬盘存储的...
看了前面的几篇Spark博客,相信大家对于Spark的基本概念以及不同模式下的环境部署问题已经搞明白了。但其中,我们曾提到过Spark...文章目录RDD概述1.什么是RDD2.R...
熟悉并掌握PPT中的RDD算子
RDD常用转换算子和动作算子
标签: spark
对RDD中的每个元素都执行一个指定的函数来产生一个新的RDD 任何原RDD中的元素在新的RDD中都有且只有一个元素与之对应 输入分区和输出分区一一对应 //创建一个spark context对象 val conf:SparkConf = new Spark
RDD基本算子
RDD-API创建RDD三种方法RDD的方法/算子分类Transformation转换算子Action动作算子统计操作基础练习[快速演示]准备工作案例1. WordCount2. 创建RDD3. 查看该RDD的分区数量4. map5. filter6. flatmap7. sortBy8. 交集...
推荐文章
- Android 编译so文件 MP4V2_android下编译mp4v2-程序员宅基地
- 通讯录Contact_02_contact文件内容-程序员宅基地
- Qt笔记(四十二)之QZXing的编译 配置 使用_qzxingfilterrunnable error:-程序员宅基地
- 关于画图软件Dia打开程序始终为英文界面的问题-程序员宅基地
- OpenCV从入门到精通实战(二)——文档OCR识别(tesseract)-程序员宅基地
- 详解avcodec_receive_packet 11_avcodec_receive_packet eagain-程序员宅基地
- OpenGL SuperBible 7th源码编译记录_superbible7-media github-程序员宅基地
- Wireshark简单使用-程序员宅基地
- MXNet 粗糙的使用指南_iou loss mxnet-程序员宅基地
- iOS对ipa包进行代码混淆《二》 ---代码混淆_ipa包混淆-程序员宅基地