
”stable-diffusion“ 的搜索结果
这里分为三个部分:1. 提示词 2. 符号的使用 3. 图像的输出1. 提示词提示词分为正向和反向的生成图像时,我们可以使用正向提示词来指定想要生成的图像。正向提示词可以是脑子里想到的图片或一句话,将其拆分成不同的...
stable-diffusion-webui Restore faces Error 【https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/1513】 我认为这与损坏的安装有关。就我而言,我在“\models\Codeformer”上的 Codeformer.pth 已...
ControlNet在大型预训练扩散模型(Stable Diffusion)的基础上实现了更多的输入条件,如边缘映射、分割映射和关键点等图片加上文字作为Prompt生成新的图片,同时也是stable-diffusion-webui的重要插件。ControlNet...
stable diffusion是一个文生图模型,主要由CompVis、Stability AI和LAION的研究者们创建。这个模型主要是在512X512分辨率的图像上训练的,训练数据集是LAION-5B,该数据集是目前可访问的最大的多模态数据集。
stable diffuion
从图中可看出,与 AMD 或英特尔的任何产品相比,...Stable Diffusion Web UI提供了易于使用的图形界面,可以帮助用户更直观地了解和使用Stable Diffusion的功能,并在基本不需要编写代码的情况下启动和监视训练过程。
AI绘图,Stable-Diffusion WEBUI,本地化(简体中文)语言文件。 原始文件来自翻译插件,根据自己实际使用情况,增加和修改了一些翻译。 配合【双语插件】看上去要自然一点,内容还在继续完善中。 本次增加了一些...
AI-绘画的工具准备:Stable-Diffusion使用教程
下载解压后放入extension文件夹下即可
通过Gradio库,实现Stable Diffusion web 管理接口。

stable-diffusion-webui安装过程中的一些问题以及解决方案
打开v2-1_768-ema-pruned.ckpt · stabilityai/stable-diffusion-2-1 at main(https://huggingface.co/stabilityai/stable-diffusion-2-1/blob/main/v2-1_768-ema-pruned.ckpt),下载训练模型(大小4.9G)。...
记录工作,工作复盘电脑配置情况大致记录如下,请参考:MSI移动工作站,64G内存,4GB显存。
python:版本是3.10.11,这个版本会比较合适...百度:Downloading: "https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly。然后等待有出现http:/0.0.0.0:7860就说明已启动成功。
本文是一个简单介绍stable-diffusion-webui部署流程的文章。
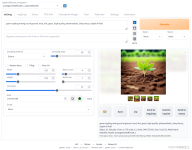
Docker容器内,从零开始搭建一个Stable Diffusion Webui服务。
Stable Diffusion是2022年发布的深度学习文本到图像生成模型,它主要用于根据文本的描述产生详细图像,尽管它也可以应用于其他任务,如内补绘制、外补绘制,以及在提示词(英语)指导下产生图生图的翻译。3.1、创建stable-...
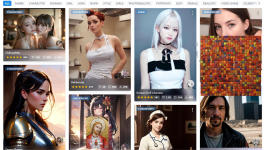
Stable Diffusion 是一个画像生成 AI,能够模拟和重建几乎任何可以以视觉形式想象的概念,而无需文本提示输入之外的任何指导
苹果公司的程序员为 M1,M2 之类的ARM64芯片专门创建了一个 stable-diffusion 的仓库,可以充分利用 M1 内置的人工智能芯片(神经网络芯片), 需要转换 PyTorch 模型为 Apple Core ML 模型。本文基于这个仓库进行操作。
运行失败,Can't load tokenizer for 'openai/clip-vit-large-patch14'stable-diffusion-webui/modules/cmd_args.py这个文件。解压models--bert-base-uncased.tar.gz。因为我放的位置是项目的同级目录所以改成下面...
最近AI绘画实现了真人照片级绘画水准,导致AI绘画大火,公司也让我研究研究,借此机会正好了解一下深度学习在AIGC(AI Generated Content)----人工智能自动内容生成领域的应用。

找到提示目录下前缀为“~”的文件夹,删除掉。
具体记录一下笔者除了按照上述教程,遇到坑的地方。
是2022年发布的深度学习文本到图像生成模型。它主要用于根据文本的描述产生详细图像,官方项目其实并不适合新手直接使用,好在有一些基于封装的webui开源项目,可以通过界面交互的方式来使用,极大的降低了使用门槛...
可能由于本机手动编译安装过其他版本Python而冲突,还是conda方便。编辑~/.condarc 内容如下即可。conda查看已安装的虚拟环境。打开一个新终端,配置源。
推荐文章
- react常见面试题_recate面试-程序员宅基地
- 交叉编译jpeglib遇到的问题-程序员宅基地
- 【办公类-22-06】周计划系列(1)“信息窗” (2024年调整版本)-程序员宅基地
- SEO优化_百度seo resetful-程序员宅基地
- 回归预测 | Matlab实现HPO-ELM猎食者算法优化极限学习机的数据回归预测_猎食者优化算法-程序员宅基地
- 苹果发通谍拒绝“热更新”,中国程序猿“最受伤”-程序员宅基地
- 在VSCode中运行Jupyter Notebook_vscode jupyter notebook-程序员宅基地
- 老赵书托(2):计算机程序的构造与解释-程序员宅基地
- 图像处理之常见二值化方法汇总-程序员宅基地
- 基于springboot实现社区团购系统项目【项目源码+论文说明】计算机毕业设计-程序员宅基地