本文总结了常用的5个参数优化器SGD SGDM AdaGrad RMSProp Adam,并总结归纳了构建网络时需要注意的一些经验
”参数更新“ 的搜索结果

今天小编就为大家分享一篇关于pytorch中网络loss传播和参数更新的理解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
神经网络的学习的目的是找到使损失函数的值尽可能小的参数。这是寻找最优参数的问题,解决这个问题的过程称为。但是神经网络的最优化问题非常难。这是因为参数空间非常复杂,无法轻易找到最优解。而且,在深度神经...
pytorch中的参数更新过程的实例讲解。
主要介绍了单隐层网络的发展历程,发展期间遇到的问题机器解决方案,根据目标函数和网络结构列出其权重和阈值的递推公式,有助于加深对神经网络的理解,设计自己的网络或者目标函数。

如何更新 起因 实现随机深度策略时,在block内部进行requires_grad=True/False操作会报错(后面测试知道其实是DataParallel的锅) ref: 1, 2 结论 初始化各模块如self.conv3后,其_grad值为None self.conv3只有在...
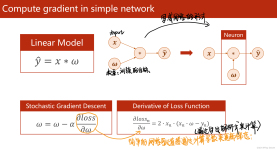
最简单的更新形式是沿负梯度方向更新参数(因为梯度指示增加的方向,但我们通常希望最小化损失函数)。设参数x和梯度dx,最简单的更新形式如下: # Vanilla update x += - learning_rate * dx 其中learning...
在用pytorch训练模型时,通常会在遍历epochs的过程中依次用到optimizer.zero_grad(),loss.backward、和optimizer.step()、lr_scheduler.step()四个函数,使用如下所示: train_loader=DataLoader( ...
一、 引言 下山问题 假设我们位于黄山的某个山腰处,山势连绵不绝,不知道怎么下山。于是决定走一步算一步,也就是每次沿着当前位置最陡峭最易下山的方向前进一小步,然后继续沿下一个位置最陡方向前进一小步...
采用整个训练集的数据来计算损失函数对参数的梯度。 SGD(Stochastic Gradient Descent) SGD,随机梯度下降算法。减少了每次迭代的计算开销,在随机梯度下降的每次迭代中,随机均匀采样的一个样本。和BGD的一次用...
一、参数更新 1.随机梯度下降及各种更新方法 【普通更新】:沿着负梯度方向改变参数 x+= -learning_rate * dx 其中学习率是一个超参数,它是一个固定的常量。 【动量更新】(Momentum) 这...
神经网络中:常见的几种参数更新方法(SGD、Momentum、AdaGrad、Adam、RMSProp、Adadelta)权值初始值、Batch Norm、过拟合、抑制过拟合

1、主机连接参数更新 1.1、LL_CONNECTION_UPDATE_REQ 连接参数第一次是主机发送的 CONNECT_REQ 中传递的。 而这个命令的使用只限主机使用,也就是说主机根据需要随时都可以进行参数更新。从机接收到这个命令后要么...
当通过反向传播来计算解析梯度时,梯度就能够被用来进行参数更新了。一般来说,进行参数更新的方法有许多种,最简单的是沿着负梯度方向逐渐改变参数的的普通方法。又或可以引入动量(Momentum)这一概念… 常见的...
一、引言 与全连接神经网络不同,卷积神经网络每一层中的...因此其权重和偏置更新公式与全连接神经网络不通。通过卷积核替代权重矩阵的意义在于:1. 降低的计算量;2. 权重得到共享,降低了参数量。 UFLDL(Unsuperv
【模型训练阶段的参数更新】
标签: ML

在pytorch中停止梯度流的若干办法,避免不必要模块的参数更新 2020/4/11 FesianXu 前言 在现在的深度模型软件框架中,如TensorFlow和PyTorch等等,都是实现了自动求导机制的。在深度学习中,有时候我们需要对某些...
最近面临换工作的问题,想把以前的算法知识捡一捡, 1、向前算法 #mermaid-svg-VhyBzTddVryJDIKa .label{font-family:'trebuchet ms', verdana, arial;font-family:var(--mermaid-font-family);...
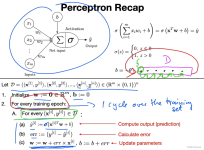
一、 神经网络的发展过程: 1. MP 神经元; 2. 感知机; 3. 多层前馈神经网络; ...4. 误差逆向传播算法;...早期的感知机只有一个MP神经元,不能处理非线性问题,甚至连最简单的“异或”问题都不能解决。...
在上一篇博客中,我简单的介绍了下线性回归模型,但是关于其参数更新方法我想单独开一篇博文来讲,毕竟这也可以单独拿出来做一个课题的切入点了。好!废话不多说!开始我的表演! 1. 引言 每个学习模型都需要制定...
相比于2018年,在ICLR2019提交论文中,提及不同框架的论文数量发生了极大变化,网友发现,提及tensorflow的论文数量从2018年的228篇略微提升到了266篇,keras从42提升到56,但是pytorch的数量从87篇提升到了252篇。...
若D_update_ratio==1,那么G和D之间是1:1的方式进行参数更新;若D_update_ratio==2,那么首先更新两次D再更新一次G。更新G的时候需要冻结D的梯度,避免其计算梯度耗费时间。 首先,fake_H是通过低分辨率的图像var_...
出现这种情况是因为依赖路由的query或params参数获取写在created生命周期里面,因为相同路由二次甚至多次加载的关系 > 没有达到监听,退出页面再进入另一个文章页面并不会运行created组件生命周期,导致文章数据还是...
根据误差值修改每层的权重,继续迭代,直到参数更新到固定值的时候,预测值与真实值的误差最小。 下面随便举一个栗子来说明~ 假设有一个样本数据,它有两个特征(L1,L2),同时,假设每个样本有两个输出(O1,O2),w...
前言 以前用Keras用惯了,fit和fit_generator真的太好使了,模型断电保存搞个...argparse是一个Python模块:命令行选项、参数和子命令解析器。 主要有三个步骤: 创建 ArgumentParser() 对象 调用 add_argument()
推荐文章
- 凯撒加密方法介绍及实例说明-程序员宅基地
- 工控协议--cip--协议解析基本记录_cip协议embedded_service_error-程序员宅基地
- 如何在vs2019及以后版本(如vs2022)上添加 添加ActiveX控件中的MFC类_vs添加mfc库-程序员宅基地
- frame_size (1536) was not respected for a non-last frame_frame_size (1024) was not respected for a non-last-程序员宅基地
- Android移动应用开发入门_在安卓移动应用开发中要在活动类文件中声迷你一个复选框变量-程序员宅基地
- java: 无法访问org.springframework.boot.SpringApplication_error:(4,32) java: 无法访问org.springframework.boot.sp-程序员宅基地
- 【kafka】解决kafka-tool连接上kafka,brokers和topics不显示问题_kafka ui中显示topic 但是命令行中不显示-程序员宅基地
- OpenCV在visual studio 2022中的下载与配置_visual stdudio2022和opencv-程序员宅基地
- python Dataframe_创建空的pd.dataframe-程序员宅基地
- javajavajava环境变量_javajava环境变量配置-程序员宅基地