大数据组件使用 总文章
标签: 大数据组件使用
日萌社:http://www.rimengshe.com ... ... 【日萌社】用户画像 【日萌社】C、C++笔记 【日萌社】JavaWeb+大数据笔记 【日萌社】CDH 6、CDH5 【日萌社】Python笔记 【日萌社】Keras、PyTorch 【日萌社】日语语...
标签: 大数据组件使用
日萌社:http://www.rimengshe.com ... ... 【日萌社】用户画像 【日萌社】C、C++笔记 【日萌社】JavaWeb+大数据笔记 【日萌社】CDH 6、CDH5 【日萌社】Python笔记 【日萌社】Keras、PyTorch 【日萌社】日语语...
https://blog.csdn.net/JENREY/article/details/80643970
大数据领域主要是以java为主,次要的编程语言为python,scala等,本文介绍和python相关的大数据: python所需要的版本为python3.6: 数据源: MySQL: oracle: MS SQL server: postgresql: pip install psycopg...
一、前一篇介绍的是ambari的安装, 1、通过页面登录进入的画面如下:... 2、创建集群。 ...Select Version–HDP-2.6.1.0–Use Local Repository–redhat7 详见下图: ...删除不需要的那些版本,选择redhat7这个版本
网上找了大数据学习相关的资料用作学习和复习使用,基本上没有全面的复习资料,特此自己基于理解,浅显的罗列大数据相关组件作用及使用方法(含实时和离线数据采集),用作复习使用;点赞过百,更新各组件详解,不足...

使用Ambari整合的各大数据组件版本(hadoop,spark,hbase,phoenix)等
离线计算组件 1.1 hive hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类...
链接: 学习建议,大数据组件那么多,可以重点学习这几个。
标签: hadoop
大数据基础组件 Hadoop 大数据生态圈 HDFS 分布式文件存储系统 MapReduce(MR) 基于磁盘计算 Spark(RDD) 基于内存计算 SparkSQL 一般情况都是基于离线数据处理 Spark Streaming 一般情况是基于微批(实时)处理 Flink...
nifi 是一款开源的数据集成工具,由Apache软件基金会开发和维护。...本文详细介绍了nifi的历史背景、工作原理、入门介绍、工作流程及实际应用场景和使用优势,帮助读者认识并入门这款强大的开源大数据组件。
CentOS6安装大数据软件(一):Linux基础软件的安装 CentOS6安装大数据软件(二):Hadoop分布式集群配置 CentOS6安装大数据软件(三):Kafka集群的配置 CentOS6安装大数据软件(四):HBase分布式集群的配置 ...
协议 作用 spark:// spark的standalone模式 hdfs:// 分布式文件集群 hiveserver2 beeline连接的前提 thrift/thrift2 python连接hbase的前提
5套大数据可视化界面html,可以用于开发,组件样式图表

1、离线查询引擎 pig :数据流式处理 数据仓库系统,基于hadoop的数据流执行引擎,利用mapreduce并行处理数据,使用pig Latin语言表达数据流。 Hive:HiveQL数据仓库系统 是构建在Hadoop之上的数据仓库,用于解决...
链接:https://pan.baidu.com/s/1Ad74uFae5pBFKMKNpweUvA。大数据组件一键安装(可支持离线安装,只适用于。配置工具下包含了教程视频
主要是通过在不同主机上建立多个NameNode,防止由于一台主机失去作用而导致集群失效,配置hadoop高可用,可以自动的使其他主机处于从standby转化为active状态
组件名称 没啥用的理由 phoenix 不支持最新版Hbase Ambari 不支持最新的周边组件 Zeppein 不支持最新版的Spark
数据产生是数据平台的源头,没有数据就没有大数据平台(数据产生传输处理) 数据的产生: 一.数据产生的来源分为以下几种: 1.业务系统:来自企业IT系统存储在数据库的数据 eg:POS销售系统、EPR系统、CRM系统 2.Web...
Hadoop生态圈各常用组件介绍 Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。具有可靠、高效、可伸缩的...
大数据组件之kafka部署
大数据测试用例模板下载
作者颜卫,腾讯高级后台开发工程师,专注于Kubernetes大规模集群管理和资源调度,有过万级集群的管理运维经验。目前负责腾讯云TKE大规模Kubernetes集群的大数据应用托管服务。...
项目概述:CloudEon 是一种基于 Kubernetes 的开源大数据...CloudEon 旨在通过 Kubernetes 对开源大数据组件进行一键式部署,实现资源的高效安装与运行,极大减轻对底层资源运维的关注,助力企业专注于核心业务发展。
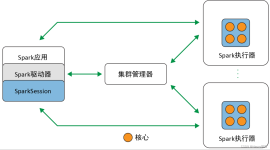

标签: 大数据
常用大数据组件的Web端口号总结