词嵌入将不定长的文本转换到定长的空间内,是文本分类的第一步。 one-hot 这里的One-hot与数据挖掘任务中的操作是一致的,即将每一个单词使用一个离散的向量表示。具体将每个字/词编码一个索引,然后根据索引进行...
”天池-新闻文本分类“ 的搜索结果
天池零基础入门NLP - 新闻文本分类Top1方案的bert4torch复现
阿里天池-零基础入门NLP - 新闻文本分类
【NLP】天池新闻文本分类(二)——数据读取与数据分析前言数据读取数据分析 前言 NLP之新闻文本分类挑战赛(赛题链接)。 其实上一篇赛题理解时已经做了数据读取和分析,因为一般在分析之后才对题目有初步理解。但...
【NLP】天池新闻文本分类——赛题理解赛题介绍赛题数据评测标准赛题理解读取数据分析数据解题思路 赛题介绍 NLP之新闻文本分类挑战赛(赛题链接)。 赛题以自然语言处理为背景,要求选手根据新闻文本字符对新闻的...

天池学习赛零基础入门NLP - 新闻文本分类

赛题任务:赛题以自然语言处理为背景,要求选手对新闻文本进行分类,这是一个典型的字符识别问题 赛题数据由以下几个部分构成:训练集20w条样本,测试集A包括5w条样本,测试集B包括5w条样本。为了预防选手人工标注...

天池NLP赛事-新闻文本分类(一) —— 赛题理解 天池NLP赛事-新闻文本分类(二) —— 数据读取和数据分析 天池NLP赛事-新闻文本分类(三)——基于机器学习的文本分类 目录三、基于机器学习的文本分类3.1 机器学习...

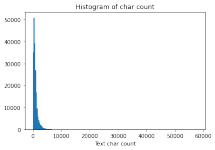
天池:零基础入门NLP - 新闻文本分类赛题理解解题思路 赛题理解 赛题链接: https://tianchi.aliyun.com/competition/entrance/531810/information 划重点: 字符级匿名处理(防止人工标注答案)、14个分类类别(0-...

天池零基础入门NLP-新闻文本分类比赛代码分享
赛题数据为新闻文本,并按照字符级别进行匿名处理。整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐的文本数据。赛题数据由以下几个部分构成:...
【阿里云天池算法挑战赛】零基础入门NLP - 新闻文本分类-Day1-赛题理解_202xxx的博客-程序员宅基地 二、数据读取与数据分析 【阿里云天池算法挑战赛】零基础入门NLP - 新闻文本分类-Day2-数据读取与数据分析_202xxx的...
以下资料整理自比赛论坛,感谢这些无私开源的选手们,以下是整理TOP5方案的主要思路和模型,...零基础入门NLP - 新闻文本分类比赛方案分享 nano- Rank1 代码:https://github.com/kangyishuai/NEWS-TEXT-CLASSIFICA...
天池NLP赛事-新闻文本分类(一) —— 赛题理解 天池NLP赛事-新闻文本分类(二) —— 数据读取和数据分析 目录二、数据读取与数据分析2.1 数据读取2.2 数据分析2.2.1 句子长度分析2.2.2 新闻类别分布2.2.3 字符分布...
文章目录一、HF模型预训练方式1.加载数据集:2.训练tokenizer2.2 分词器的训练参数如下:2.3 分词器保存和加载3.从头开始训练语言模型3.2 初始化模型3.3 创建训练集3.4 初始化 Trainer并训练5. 检查训练好的模型 ...
天池NLP赛事-新闻文本分类(一) —— 赛题理解 天池NLP赛事-新闻文本分类(二) —— 数据读取和数据分析 天池NLP赛事-新闻文本分类(三)——基于机器学习的文本分类 天池NLP赛事-新闻文本分类(四)——基于深度...
天池阿里云 - 零基础入门NLP - 新闻文本分类前言赛题理解数据观察特征工程模型构建结果分析 前言 本次的比赛分析是基于天池阿里云的零基础入门NLP比赛。 比赛连接:...
基于LTSM天池新闻文本分类比赛python源码.zip 1、该资源内项目代码都是经过测试运行成功,功能ok的情况下才上传的,请放心下载使用! 2、本项目适合计算机相关专业(如计科、人工智能、通信工程、自动化、电子信息等)...
基于LTSM天池新闻文本分类比赛python源码(高分课程设计).zip 已获导师指导并通过的97分的高分期末大作业设计项目,可作为课程设计和期末大作业,下载即用无需修改,项目完整确保可以运行。 基于LTSM天池新闻文本...
数据读取 import pandas as pd train_df = pd.read_csv('../data/train_set.csv', sep='\t', nrows=100) # 查看基本信息,label text train_df.head() 句子长度分析 %pylab inline train_df['text_len'] = train_df...
二、分字处理及文本清洗 该部分涉及tokenization.py 1. CharacterRecognition类 该类中存放一些字符识别函数, 判断是否为whitespace、control、punctuation、chinese_char。 class CharacterRecognition: ...
天池NLP赛事-新闻文本分类(一) —— 赛题理解 天池NLP赛事-新闻文本分类(二) —— 数据读取和数据分析 天池NLP赛事-新闻文本分类(三)——基于机器学习的文本分类 天池NLP赛事-新闻文本分类(四)——基于深度...
推荐文章
- 服务器无法与DeviceNetBT_Tcpip_{670E1543-79C1-485C-9B4B-835CE3BA37B3}传输相绑定-程序员宅基地
- NYOJ 118 修路方案(次小生成树)-程序员宅基地
- 【期末复习】微机原理与接口技术_己知 8254 的端口地址为 3000h、3004h3008h 和 30bh外接时钟频率为 2mh2-程序员宅基地
- 2D转换,动画,转化-程序员宅基地
- 旋转拖动验证码解决方案_load_model("keras2.hdf5", custom_objects={'angle_e-程序员宅基地
- Windows下后台静默运行jar包_windows下启jar包关闭窗口不听-程序员宅基地
- windows7的aero的介绍-程序员宅基地
- libevent与libev简介_libevent libev-程序员宅基地
- zookeeper启动Error: JAVA_HOME is incorrectly set问题解决_error: java_home is incorrectly set: e:\java\jdk1.-程序员宅基地
- 操作系统概述_多道批处理系统算不算操作系统-程序员宅基地