我们的所有非技术内容和活动,从现在开始会使用 iBooker 这个名字。 “开源互助联盟”已终止,我们对此表示抱歉和遗憾。除非特地邀请,我们不再推广他人的任何项目。 公众号自动回复已更新,添加了“轻小说/知识星球...
”数据科学从0到1“ 的搜索结果
Python的int型写入Excel时会有两种潜在问题(参考https://support.office.com/en-us/article/display-numbers-in-scientific-exponential-notation-f85a96c0-18a1-4249-81c3-e934cd2aae25?ui=en-US&rs=en-US&...


一、数据科学的生命周期 原文:DS-100/textbook/notebooks/ch01 译者:飞龙 协议:CC BY-NC-SA 4.0 自豪地采用谷歌翻译 在数据科学中,我们使用大量不同的数据集来对世界做出结论。在这个课程中,我们...
f=load('temp.txt');... fprintf(fw,'%.6g %.6g %.6g\n',f(index,1),f(index,2),f(index,3)); fprintf(fw,'%.6g %.6g %.6g\n',f(index,4),f(index,5),f(index,6)); fprintf(fw,'%.6g %.6g %.6g\n\n',f(index,
近期项目应用查询中有遇到达梦7或达梦8表中列的数据类型为number类型,查询小数点后5位0+任意数字超过6位后,查询结果集显示成科学计数法了,达梦8测试如下图: 经过查询达梦8手册,这种情况非bug,可采取类型转换...
一、数据科学工作流程1.1 数据导入 1.2 数据整理 1.3 反复理解数据 1.4 数据可视化 1.5 数据转换 1.6 统计建模 1.7 作出推断(比如预测) 1.8 沟通交流 1.9 自动化分析 2.0 程序开发二、每个步骤最有用的...

7.2 数据整理 原文:Data Wrangling ...直接从 GitHub 挖掘数据,Viz由 GitHub API 提供支持,并利用以下内容: 通过 Python 使用github3.py 访问 GitHub API。 将下面的 IPython 笔记本 中的pandas用于数据整理...

我们是一个大型开源社区,旗下 QQ 群共 9000 余人,Github Star 数量超过 20k 个,网站日 uip 超过 4k,拥有 CSDN 博客专家和简书程序员优秀作者认证。我们组织公益性的翻译活动、学习活动和比赛组队活动,并和 ...
本节是《Python 数据科学手册》(Python Data Science Handbook)的摘录。 我们已经看到GroupBy抽象如何让我们探索数据集中的关系。透视表是一种类似的操作,常见于电子表格,和其他操作表格数据的程序中。透视表将...

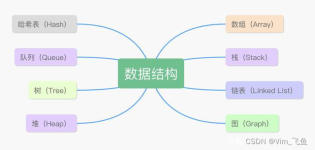
各个中间件开发者,架构师他们都在努力的优化中间件、项目结构以及算法提高运行效率和降低内存占用,在这里数据结构起到相当重要的作用。此外数据结构也蕴含一些面向对象的思想,故学好掌握数据结构对逻辑思维处理...
导出的数据出现科学计数法问题,像电话号码,身份证号码,当数据大于15位后面的会用0替代。针对这一问题,解决方法如下: 就是再数字前加上制表符“\t”注意双引号,拼接字符串来实现 例如: 在导出数据时,进行拼接...

NumPy是Python中重要的第三方库,提供高效的数据结构和计算时间节省。文章介绍了NumPy数组的创建和处理,结构数组的定义,以及ufunc函数的使用。此外,还介绍了NumPy的连续数组创建、算数运算和统计函数的应用,以及...
今天在将dataframe数据写入excel的时候,出现了较小的小数如0.0000567写入excel时变成了科学计数法5.67E-5,在网上找了很多方法最终解决这个问题。 (感谢这位博主...

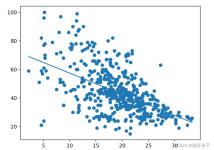
五、探索性数据分析 原文:DS-100/textbook/notebooks/ch05 译者:飞龙 协议:CC BY-NC-SA 4.0 自豪地采用谷歌翻译 ...在探索性数据分析(EDA),也就是数据科学生命周期的第三步中,我们总...


本节是《Python 数据科学手册》(Python Data Science Handbook)的摘录。 NumPy 的一个重要部分是能够执行快速的逐元素运算,包括基本算术(加法,减法,乘法等),和更复杂的运算(三角函数,指数函数和对数函数...
数据科学很难成为没有数据的科学。 因此重要的是,我们通过了解我们的数据是如何生成的,来启动任何数据分析。 在本章中,我们将讨论数据来源。 虽然术语“数据来源”通常指的是数据的整个历史,以及它随时间变化的...
R语言实现bagging和随机森林
推荐文章
- cocos creator 实现截屏截图切割转成 base64分享--facebook小游戏截图base64分享,微信小游戏截图分享【白玉无冰】每天进步一点点_cocos上传base64-程序员宅基地
- Docker_error running 'docker: compose deployment': server-程序员宅基地
- ChannelSftp下载目录下所有或指定文件、ChannelSftp获取某目录下所有文件名称、InputStream转File_channelsftp.lsentry获取文件全路径-程序员宅基地
- Hbase ERROR: Can‘t get master address from ZooKeeper; znode data == null 解决方案_error: can't get master address from zookeeper; zn-程序员宅基地
- KMP的最小循环节_kmp求最小循环节-程序员宅基地
- 详解ROI-Pooling与ROI-Align_roi pooling和roi align-程序员宅基地
- Imx6ull开发板Linux常用查看系统信息指令_armv7 processor rev 2 (v7l)-程序员宅基地
- java SSH面试资料-程序员宅基地
- ant design vue table 高度自适应_对比1万2千个Vue.js开源项目发现最实用的 TOP45!火速拿来用!...-程序员宅基地
- 程序员需要知道的缩写和专业名词-程序员宅基地