大数据新闻是一种融合了大数据技术和新闻报道的形式,通过数据驱动和可视化呈现,揭示新闻事件的趋势和规律。例如,可以通过分析选民的推特活动和社交媒体评论,预测选民的倾向和支持率,为候选人的竞选活动提供参考...
”新闻数据“ 的搜索结果
利用GDELT下载新闻数据,并进行处理和可视化
机器学习中搜狗实验室发布的搜狗新闻数据集
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

今日头条38万条新闻数据,可用于文本分类模型训练,可用LSTM模型训练
新闻系列的分享进入尾声了,在开启这个系列前,我说过一个目标是,让 nlper 有足够多的新闻语料数据集去训练。 不知不觉中,新闻聚合网站(https://xt98.tech:9494) 自从 2021/03/28 上线以来,已经稳定运行 3 个月...


python爬虫实战

新闻数据爬取

新闻数据抓取 这篇文章,主要是记录自己学习爬虫过程。 整篇部分会分为2篇文章, 1,爬取http的网页(新闻网站):获取各类主题的新闻的内容,eg:金融,体育,娱乐等等。 2,爬取https的网页(豆瓣):获取...
SougoCS数据集,内含11类搜狐新闻文本,近10万条。 搜狗提供的数据为未分类的XML格式。 此资源已经将XML解析并分类完毕,方便使用。

爬取的搜狐新闻数据,一共有12个类别,分好类了
50000条新闻文本数据集,文本有9类。可用于文本分类模型训练。
新闻类中文文本分类数据集
标签: 11
资源为新闻类的中文文本分类数据集,能够满足机器学习,文字分析方面的需求
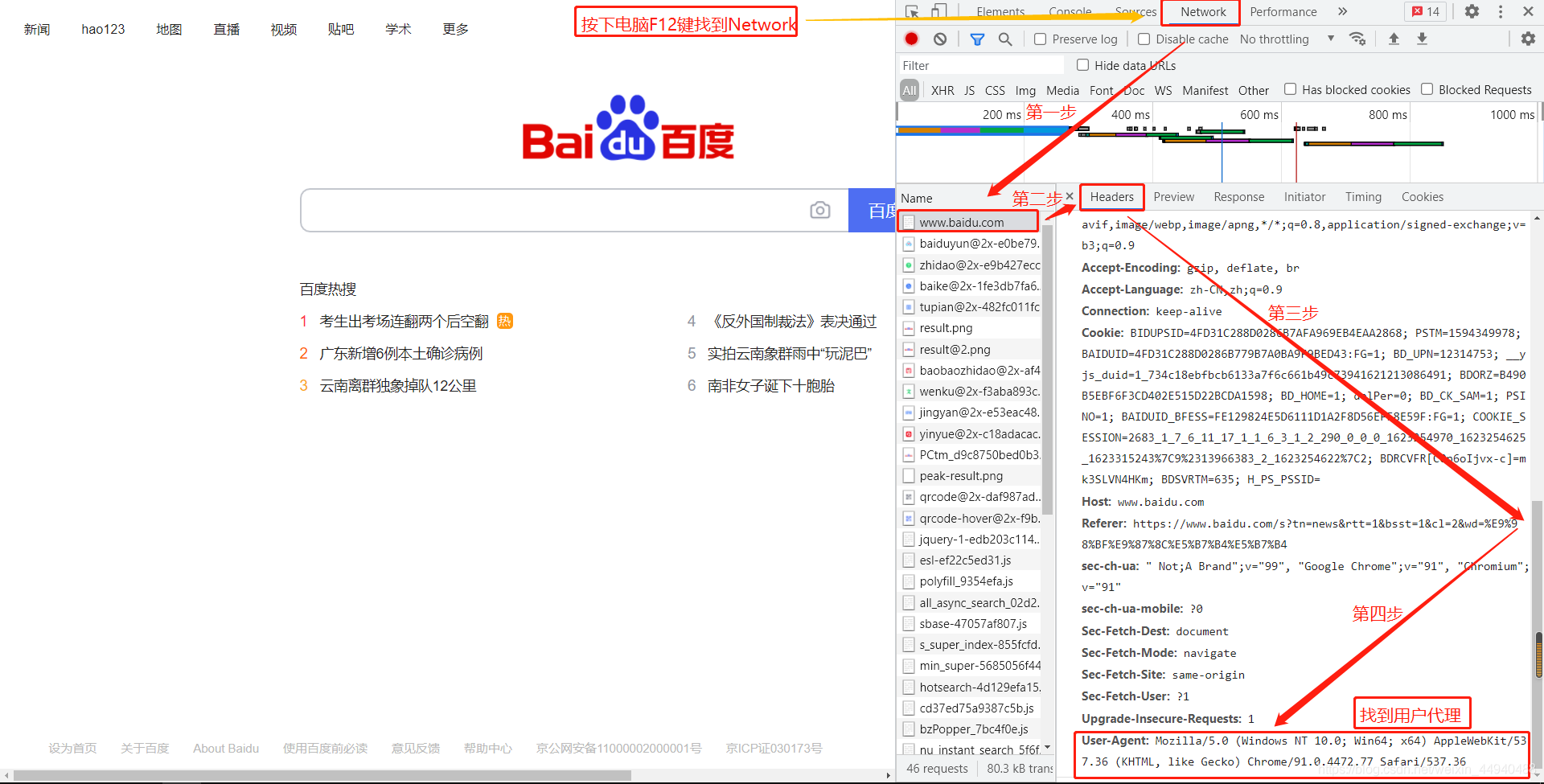
1. 爬虫的浏览器伪装原理: 我们可以试试爬取csdn博客,我们发现会返回403 ,因为对方服务器会对爬虫进行屏蔽。此时,我们需要伪装成浏览器才能爬取。 2.实战分析: 浏览器伪装一般通过报头进行: ...


此文基于“搜狗实验数据库”的海量新闻数据,全流程展示如何基于tensorflow采用CNN算法实现文章的分类。方便学习者全面地理解深度学习及NLP文本分析的原理和实现步骤。 二、数据预处理 此部分详细代码见《如何有效...
凤凰网热点新闻 查看网页源代码,发现每个排行的数据在标签<div class="boxTab clearfix">中,共五个div标签 import requests from bs4 import BeautifulSoup url = 'http://news.ifeng.com/hotnews/' ...

下载语料库进入搜狗实验室下载搜狐新闻数据,得到的是news_sohusite_xml.full.tar.gz这个压缩包,我们下载的是完整版的。 数据预处理原始数据中包含完整的html文件,所以需要提取其中的中文内容,我们只提取其中&...


在之前的闲聊对话语料中提到,爬取了400w+新闻语料训练word2vec,考虑到这个平台数据质量比较高,但是爬取的时候又有频率限制、网页打开慢、甚至有时候需要多次访问才能打开网页,经过几个月断断续续地爬取,在此把...
推荐文章
- 内网穿透 篇四:通过 Cloudflare Tunnel 内网穿透 实现公网访问内网服务-程序员宅基地
- QT 如何把外部程序嵌入到QT界面_qt嵌入外部程序-程序员宅基地
- 苍穹外卖day8(2)用户下单、微信支付
- 伯克利大模型排名-程序员宅基地
- 【已解决】Python的坑:os.system()运行带有空格的长路径和双引号参数有bug_os.system怎么调试-程序员宅基地
- 基于FPGA的交通灯系统_vivado实例交通灯-程序员宅基地
- MLP理解_mlp是什么意思-程序员宅基地
- zabbix监控深信服_zabbix3 通过snmpv3监控linux主机-程序员宅基地
- u-boot与Linux内核视频显示接口参数配置及传递方案_uboot读取显示器的分辨率-程序员宅基地
- SQL Server 2005怎么使用sa实现远程登录_远程登陆的sa是什么组-程序员宅基地