
”自注意力“ 的搜索结果

自注意力机制
自注意力机制(Self-Attention),有时也称为内部注意力机制,是一种在深度学习模型中应用的机制,尤其在处理序列数据时显得非常有效。它允许输入序列的每个元素都与序列中的其他元素进行比较,以计算序列的表示。...
一文带你读懂注意力机制、自注意力机制、多头注意力机制、通道注意力机制、空间注意力机制,超详细的讲解,小白也能看得懂!

自注意力与文本分类 依赖 Python 3.5 Keras 数据集 IMDB影评倾向分类数据集,来自IMDB的25,000条影评,被标记为正面/负面两种评价。影评已被预处理为词下标构成的序列。方便起见,单词的下标基于它在数据集中出现的...
1 Self-Attention的概念2 Self-Attention的原理3 Self-Attention的作用4 Self-Attention的问题。
简单理解:多组自注意力机制并行运行,最后把结果拼接起来。

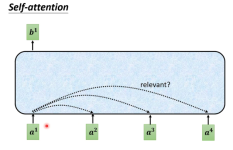

总而言之,卷积神经网络和自注意力都拥有并行计算的优势, 而且自注意力的最大路径长度最短。但是因为其计算复杂度是关于序列长度的二次方,所以在很长的序列中计算会非常慢。而在自注意力中,查询、键和值都是。



上一节对注意力分数(Attention Score)这个概念进行了总结。本节将基于缩放点积注意力机制(Scaled Dot-Product Attention)这种注意力分数的计算模式,介绍自注意力机制。


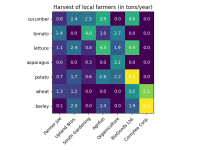

自注意力机制(Self-Attention Mechanism):自注意力机制则是在处理单一序列时使用的,例如在处理一个句子时,它可以计算句子中每个单词对于其它所有单词的关注度。这是一种序列内部的注意力机制,因此被称为“自...
Self-Attention自注意力机制是Transformer模块的重要组成部分,是截至到现在(2024年1月6日)大大小小网络的标配,无论是LLM还是StableDiffusion,内部都有Self-Attention与Transformer,因此,一起来学学哈哈。
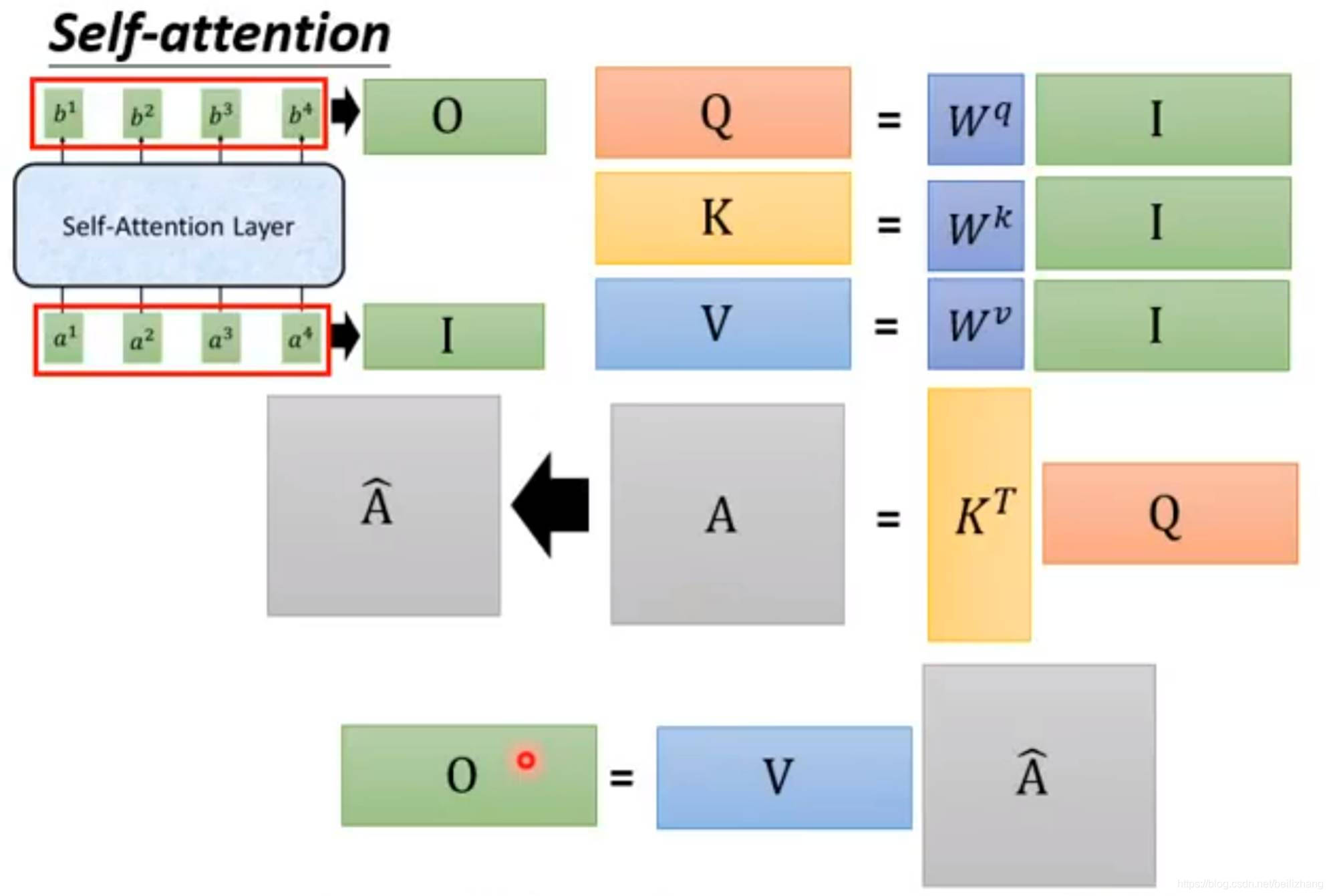

本内容主要介绍自注意力(Self-Attention)机制中的位置编码。


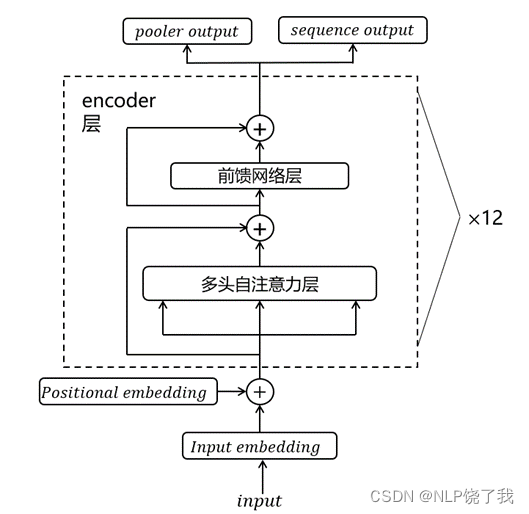
BERT(Bidirectional Encoder Representations from Transformers)是一种预训练模型,它是自然语言处理(NLP)领域的重大里程碑,被认为是当前的State-of-the-Art模型之一。BERT的设计理念和结构基于Transformer...
推荐文章
- php 上传图片 缩略图,PHP 图片上传类 缩略图-程序员宅基地
- scrapy爬虫框架_3.6.1 scrapy 的版本-程序员宅基地
- 微信支付——统一下单——java_小程序统一下单接口-程序员宅基地
- (已解决)报错 ValueError: Tensor conversion requested dtype float32 for Tensor with dtype resource-程序员宅基地
- 记录el-table树形数据,默认展开折叠按钮失效_eltable一刷新展开的子节点展开按钮消失-程序员宅基地
- 设计模式复习-桥接模式_csdn天使也掉毛-程序员宅基地
- CodeForces - 894A-QAQ(思维)_"qaq\" is a word to denote an expression of crying-程序员宅基地
- java毕业生设计移动学习网站计算机源码+系统+mysql+调试部署+lw-程序员宅基地
- 14种神笔记方法,只需选择1招,让你的学习和工作效率提高100倍!_1秒笔记 高级-程序员宅基地
- 最新java毕业论文英文参考文献_计算机毕业论文javaweb英文文献-程序员宅基地